

EN
Multithreading Issues
Setting a num_workers value greater than 0 on Windows may cause errors.
Refer to: https://discuss.pytorch.org/t/errors-when-using-num-workers-0-in-dataloader/97564/3
The above implementation might encounter race conditions during actual reproduction.
My Implementation
Create the relevant class externally:
1 | # cat_dog_dataset.py |
Then call it in the original code:
1 | from cat_dog_dataset import CatDogDataset |
The specific reason might be as follows:
When I put the CatDogDataset class in an external file and import it in the original code, the reason why the four threads successfully run is due to some special handling mechanisms in Python’s multiprocessing module when importing external modules.
In a multithreading or multiprocessing environment, importing modules may involve a module lock to ensure that multiple threads or processes do not import the same module simultaneously, thus avoiding potential race conditions. Python’s multiprocessing module handles these details to ensure that modules are correctly loaded in multiple processes.
Specifically, when importing a module in a multiprocessing environment, Python uses the multiprocessing module to handle the import process, ensuring the module is loaded only once and then shared among the processes. This prevents duplicate loading and race condition issues during module imports.
So, in my case, when I put the CatDogDataset class in an external file and import it in the original code, the multiprocessing module ensures that the module is correctly loaded in multiple threads, allowing multiple threads to successfully load the dataset. This is an optimization mechanism in Python’s multiprocessing module.
After reproducing multithreading on Windows, we need to find the most suitable number of threads on our own device.
The larger the num_workers, the faster it is not necessarily.
When num_worker is not 0, each time the dataloader loads data, the dataloader creates num_worker workers at once, and uses the batch_sampler to assign the specified batch to the specified worker. The worker loads the batch it is responsible for into RAM.
The advantage of setting a large num_worker is that the batch retrieval speed is fast because the batch of the next iteration is likely already loaded in the previous iteration. The downside is that it consumes a lot of memory and increases the CPU burden (since the worker loads data into RAM through CPU copying). The experience value for setting num_workers is the number of CPU cores on your computer/server. If the CPU is strong and the RAM is sufficient, it can be set larger.
When num_worker is small, after the main process collects the last worker’s batch, it needs to go back to collect the second batch generated by the first worker. If the worker has not finished collecting at this time, the main thread will be stuck waiting here. (This happens when the number of num_works is small or the batch size is small, and the GPU finishes computing quickly, but the CPU cannot keep up with the GPU.)
That is, the value of num_workers is related to the speed of model training but has nothing to do with the performance of the trained model.
The most suitable num_works value is related to the dataset, as the process of the worker loading data into RAM is CPU copying, and the size of the dataset will affect the CPU copying process pressure. (== Different machines, different dataset sizes, and different batch_sizes may affect the optimal num_workers value. Therefore, the optimal value on one machine may not be applicable on another machine. ==)
It is best to run the following code before running the training code to choose the most suitable num_workers value:
1 | from time import time |
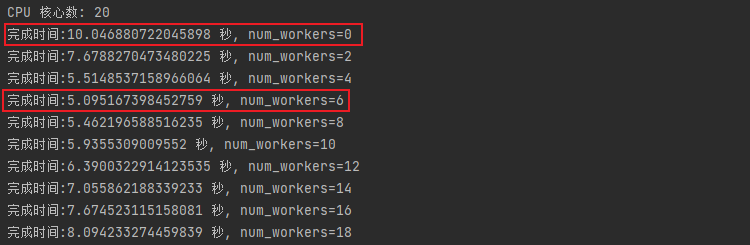
As you can see, this server has 20 CPUs, and the most suitable num_workers value for this dataset is 6.
Of course, you can also test for your own dataset to find the most suitable num_workers value. For example, for mine:
1 | import os |

Similarly, we can find the best num_workers for the validation set:
1 | import os |
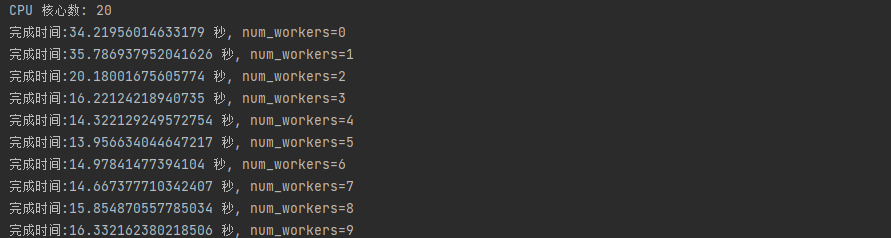
However, considering the actual running process involves running both the training set and validation set together, there are still some differences. The actual test shows that the highest efficiency is achieved when both num_workers are 4.
num_workers both set to 0:
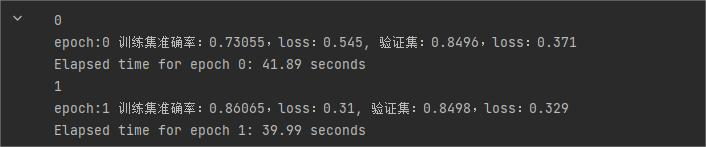
num_workers both set to 4:

Almost twice as fast.
References:
https://blog.csdn.net/hxxjxw/article/details/119531239
https://stackoverflow.com/questions/53998282/how-does-the-number-of-workers-parameter-in-pytorch-dataloader-actually-work
https://discuss.pytorch.org/t/errors-when-using-num-workers-0-in-dataloader/97564
Path or Model Naming Issues
1 | # Save the model to the current working directory using a relative path without specifying a path |
Error: RuntimeError: File 猫狗分类自定义网络.h5 cannot be opened.
1 | # Save the model to the current working directory using a relative path without specifying a path |
Successfully ran.
Some file systems or operating systems may not fully support non-English characters as filenames. When using English characters, the encoding and decoding of filenames are generally more reliable. Using English filenames is usually a safer practice when working across platforms or file systems.
AttributeError: ‘NoneType’ object has no attribute ‘int’
The following code produces an error:
1 | track_ids = results[0].boxes.id.int().cpu().tolist() |
Problem description: I am creating custom code using Yolov8 + tracker to perform detection, identify objects, and create a CSV file containing GPS RTK coordinates for each detection. I encountered an issue where the system returns the following error when no objects are detected in the video:
AttributeError: 'NoneType' object has no attribute 'int'
Refer to the issue:
Yolov8 tracker weird behavior (AttributeError: ‘NoneType’) · Issue #4315 · ultralytics/ultralytics
Solution
Use the following structure:
1 | results = model.track(frame, imgsz=img_size, persist=True, conf=conf_level, tracker=tracker_option) |
error: (-2:Unspecified error) The function is not implemented. Rebuild the library with Windows
This is usually an issue with version dependencies.
Refer to:
🐕 c++ - OpenCV GTK+2.x error - “Unspecified error (The function is not implemented…)” - Stack Overflow
Solution
1 | pip uninstall opencv-python |
Then reinstall:
1 | pip install opencv-python |
Finally, remove opencv-python-headless:
1 | pip uninstall opencv-python-headless |
CN
多线程问题
在 windows 上设置大于 0 的 num_workers 数量可能会导致错误
参见:https://discuss.pytorch.org/t/errors-when-using-num-workers-0-in-dataloader/97564/3
上面实现方法在实际复现时,我会碰到条件竞争的问题
我的实现方法
在外部创建相关的类
1 | # cat_dog_dataset.py |
然后在原来代码中调用
1 | from cat_dog_dataset import CatDogDataset |
具体的原因可能如下:
当我将 CatDogDataset 类放在一个外部文件中,并在原始代码中导入时,四个线程成功运行的原因是因为Python的multiprocessing模块在导入外部模块时有一些特殊的处理机制。
在多线程或多进程环境中,导入模块可能会涉及到模块锁(module lock),以确保多个线程或进程不会同时导入同一个模块,从而避免潜在的竞争条件。Python中的multiprocessing模块会处理这些细节,以确保模块在多个进程中被正确加载。
具体来说,当我在多进程环境中导入一个模块时,Python会使用multiprocessing模块来处理导入过程,确保模块只被加载一次,然后在各个进程之间共享。这样可以避免导入模块时可能出现的重复加载和竞争条件问题。
所以,在我的情况下,当我将 CatDogDataset 类放在一个外部文件中,并在原始代码中导入它时,multiprocessing模块确保了在多个线程中正确加载该模块,因此我可以成功运行多个线程加载数据集。这是Python多进程导入模块的一种优化机制。
在实现win上多线程的复现后,我们需要找到自己设备上最合适的线程数量
num_workers并不是设置的越大就越快的
当num_worker不为0时,每轮到dataloader加载数据时,dataloader一次性创建num_worker个worker,并用batch_sampler将指定batch分配给指定worker,worker将它负责的batch加载进RAM。
num_worker设置得大,好处是寻batch速度快,因为下一轮迭代的batch很可能在上一轮/上上一轮…迭代时已经加载好了。坏处是内存开销大,也加重了CPU负担(worker加载数据到RAM的进程是CPU复制的嘛)。num_workers的经验设置值是自己电脑/服务器的CPU核心数,如果CPU很强、RAM也很充足,就可以设置得更大些。
num_worker小了的情况,主进程采集完最后一个worker的batch。此时需要回去采集第一个worker产生的第二个batch。如果该worker此时没有采集完,主线程会卡在这里等。(这种情况出现在,num_works数量少或者batchsize 比较小,显卡很快就计算完了,CPU对GPU供不应求。)
即,num_workers的值和模型训练快慢有关,和训练出的模型的performance无关
最合适的num_works值与数据集有关,因为worker加载数据到RAM的进程是CPU复制,而数据集的大小会影响CPU复制过程的压力(==不同的机器、不同的数据集大小、不同的batch_size可能会影响最佳的num_workers值。所以最佳的值在一台机器上可能不适用于另一台机器。==)
最好是跑代码之前先用下面这段代码跑一下,选择最合适的num_workers值
1 | from time import time |
可以看到,这个服务器20个CPU, 在此数据集下最合适的num_workers值是6
当然,你也可以为自己的数据集进行进行测试,而找出最适合的num_workers,如对于我的下
1 | import os |
同样的,我们可以找到验证集的最佳num_workers,如下:
1 | import os |
但考虑到实际运行过程中训练集和验证集在一起跑的,所以还是有些差异,实测当两个num_workers都为4时,效率最高
num_workers都为0时

num_workers都为4时
差不多快了一半
参考:
https://blog.csdn.net/hxxjxw/article/details/119531239
https://stackoverflow.com/questions/53998282/how-does-the-number-of-workers-parameter-in-pytorch-dataloader-actually-work
https://discuss.pytorch.org/t/errors-when-using-num-workers-0-in-dataloader/97564
路径或模型命名问题
1 | # 不指定路径,使用相对路径保存模型到当前工作目录 |
报错:RuntimeError: File 猫狗分类自定义网络.h5 cannot be opened.
1 | # 不指定路径,使用相对路径保存模型到当前工作目录 |
成功运行
某些文件系统或操作系统可能不完全支持非英文字符作为文件名。当使用英文字符时,文件名的编码和解码通常更可靠。如果你在跨平台或跨文件系统工作时,使用英文文件名通常是更安全的做法。
AttributeError: ‘NoneType’ object has no attribute ‘int’
如下代码报错
1 | track_ids = results[0].boxes.id.int().cpu().tolist() |
问题描述:我正在创建一个自定义代码,使用 Yolov8 + 跟踪器执行检测,以识别对象,并为每次检测创建一个包含 gps RTK 坐标的 csv 文件。我遇到了一个问题,当我的视频没有检测到对象时,系统会返回以下错误:
AttributeError: 'NoneType' object has no attribute 'int'
参考issue:
Yolov8 tracker weird behavior (AttributeError: ‘NoneType’) · Issue #4315 · ultralytics/ultralytics
解决方法
用如下结构:
1 | results = model.track(frame, imgsz=img_size, persist=True, conf=conf_level, tracker=tracker_option) |
error: (-2:Unspecified error) The function is not implemented. Rebuild the library with Windows,
一般是版本依赖关系的问题
参考:
解决方法
1 | pip uninstall opencv-python |
然后重新下载:
1 | pip install opencv-python |
最后再删除opencv-python-headless:
1 | pip uninstal opencv-python-headless |