

Java字符串处理
Java定义字符串
Java没有内置的字符串类型,而是提供了一个String类来创建和操作字符串。
字符串一共有两种定义方法,如下:
直接定义字符串:指使用双引号表示字符串中的内容。
1 | String str = "Hello Java"; |
使用String类定义:因为Java中每个双引号定义的字符串都是String类的对象,索引可以用String类的构造方式来创建字符串。(该类位于java.lang包中)
String类构造方法有多种重载形式,每种形式都可以定义字符串,如下:
1.String():初始化一个新创建的String对象,表示一个空序列。
2.String(String original):初始化一个新创建的 String 对象,使其表示一个与参数相同的字符序列。换句话说,新创建的字符串是该参数字符串的副本(引用)。
1 | String str1 = new String("Hello Java"); |
3.String(cahr[] value):分配一个新的字符串,将参数中的字符数组元素全部变为字符串。该字符数组的内容已被复制,后续对字符数组的修改不会影响新创建的字符串。
1 | char a[] = {'H','e','l','l','0'}; |
上述对a数组的修改不会影响sChar的值。
4.String(char[] value,int offset,int count):分配一个新的 String,它包含来自该字符数组参数一个子数组的字符。offset 参数是子数组第一个字符的索引,count 参数指定子数组的长度。该子数组的内容已被赋值,后续对字符数组的修改不会影响新创建的字符串。
1 | char a[]={'H','e','l','l','o'}; |
上述sChar的值是”ello”。
Java API文档
JavaAPI文档详细说明了Java中的常用类和方法的功能,开发者可以提供查阅API文档,调用应用程序接口(API)来编程。
Java 官方提供了 Java 8 在线 API 文档,网址是 http://docs.oracle.com/javase/8/docs/api/
也可以用同版的在线API中文手册查看Java 8 中文版 - 在线API中文手册 - 码工具 (matools.com)
查询 API 的一般流程是:找包→找类或接口→查看类或接口→找方法或变量。
Java String和int的相互转换
String转换为int
有两种方法:
- Integer.parseInt(str)
- Integer.valueOf(str).intValue()
案例:
1 | public static void main(String[] args) { |
输出:
1 | Integer.parseInt(str) : 123 |
在 String 转换 int 时,String 的值一定是整数,否则会报数字转换异常(java.lang.NumberFormatException)。
int转换为String
有三种方法:
- String s = String.valueOf(i);
- String s = Integer.toString(i);
- String s = “” + i;
案例:
1 | public static void main(String[] args) { |
输出:
1 | str:10 |
使用第三种方法相对第一第二种耗时比较大。在使用第一种 valueOf() 方法时,注意 valueOf 括号中的值不能为空,否则会报空指针异常(NullPointerException)。
valueOf() 、parse()和toString()
1)valueOf()
对各种数据类型,可以直接调用这种方法得到合理的字符串形式。所有的简单类型数据转换成相应于它们的普通字符串形式。任何传递给 valueOf() 方法的对象都将返回对象的 toString() 方法调用的结果。
2)parse()
parseXxx(String) 这种形式,是指把字符串转换为数值型,其中 Xxx 对应不同的数据类型,然后转换为 Xxx 指定的类型,如 int 型和 float 型。
3)toString()
toString() 可以把一个引用类型转换为 String 字符串类型,是 sun 公司开发 Java 的时候为了方便所有类的字符串操作而特意加入的一个方法
Java字符串拼接
String宗福传虽然为不可变对象,但是也可以进行拼接而产生一个新的对象,String 字符串拼接可以使用“+”运算符或 String 的 concat(String str) 方法。“+”运算符优势是可以连接任何类型数据拼接成为字符串,而 concat 方法只能拼接 String 类型字符串。
使用连接运算符“+”
“+”运算符是最简单、最快捷,也是使用最多的字符串连接方式。在使用“+”运算符连接字符串和 int 型(或 double 型)数据时,“+”将 int(或 double)型数据自动转换成 String 类型。
案例:
1 | public static void main(String[] args) { |
输出:
1 | 本次考试学生信息如下: |
使用 concat() 方法
在 Java 中,String 类的 concat() 方法实现了将一个字符串连接到另一个字符串的后面。concat() 方法语法格式如下:
1 | 字符串 1.concat(字符串 2); |
执行结果是字符串 2 被连接到字符串 1 后面,形成新的字符串。
案例:
1 | public static void main(String[] args) { |
输出:
1 | 三国演义、西游记、水浒传、红楼梦 |
注:上述的info.concat("XXX)只会产生一个运算结果,并不改变info本身的值。
连接其他类型数据
字符串也可同其他基本数据类型进行连接。比如字符串与整型、浮点型变量相连,只要用”+”运算符连接即可。
Java字符串常用方法
获取字符串长度
语法形式:字符串名.length();
字符串大小写转换
语法形式:
1 | 字符串名.toLowerCase() // 将字符串中的字母全部转换为小写,非字母不受影响 |
去除字符串中的空格
语法形式:字符串名.trim()
用法示例:
1 | String str = " hello "; |
从该示例中可以看出,字符串中的每个空格占一个位置,直接影响了计算字符串的长度。
如果不确定要操作的字符串首尾是否有空格,最好在操作之前调用该字符串的 trim() 方法去除首尾空格,然后再对其进行操作。
注意:trim() 只能去掉字符串中前后的半角空格(英文空格),而无法去掉全角空格(中文空格)。可用以下代码将全角空格替换为半角空格再进行操作,其中替换是 String 类的 replace() 方法。
1 | str = str.replace((char) 12288, ' '); // 将中文空格替换为英文空格 |
其中,12288 是中文全角空格的 unicode 编码。
提取子字符串
语法形式:
1 | str.substring(int beginIndex) //用于提取从索引位置开始至结尾处的字符串部分。 |
需要特别注意的是,对于开始位置 beginIndex, Java 是基于字符串的首字符索引为 0 处理的,但是对于结束位置 endIndex,Java 是基于字符串的首字符索引为 1 来处理的,如图4-0所示。

图4-0 字符串中的字符索引
案例:
1 | public static void main(String[] args) { |
输出:
1 | substring(0)结果:Today is Monday |
分割字符串
语法形式:
1 | str.split(String sign) |
- str 为需要分割的目标字符串。
- sign 为指定的分割符,可以是任意字符串。
- limit 表示分割后生成的字符串的限制个数,如果不指定,则表示不限制,直到将整个目标字符串完全分割为止。
使用分隔符注意如下:
1)“.”和“|”都是转义字符,必须得加“\”。
- 如果用“.”作为分隔的话,必须写成
String.split("\\."),这样才能正确的分隔开,不能用String.split(".")。 - 如果用“|”作为分隔的话,必须写成
String.split("\\|"),这样才能正确的分隔开,不能用String.split("|")。
2)如果在一个字符串中有多个分隔符,可以用“|”作为连字符,比如:“acount=? and uu =? or n=?”,把三个都分隔出来,可以用String.split("and|or")。
案例:
1 | public static void main(String[] args) { |
输出:
1 | 所有颜色为: |
从输出的结果可以看出,当指定分割字符串后组成的数组长度(大于或等于 1)时,数组的前几个元素为字符串分割后的前几个字符,而最后一个元素为字符串的剩余部分。
字符串截取
语法格式:str.substring(int beginIndex,int endIndex)
注:截取的内容不包含endIndex对应的字符,截取的总个数为endIndex-beginIndex。
字符串替换
语法格式:字符串.replace(String oldChar, String newChar)
- oldChar :被替换的字符串
- newChar :用于替换的字符串
replace() 方法会将字符串中所有 oldChar 替换成 newChar。
replaceFirst() 方法
语法格式:字符串.replaceFirst(String regex, String replacement)
- regex :正则表达式
- replacement :用于替换的字符串
replaceFirst() 方法用于将目标字符串中匹配某正则表达式的第一个子字符串替换成新的字符串
replaceAll() 方法
语法格式:字符串.replaceAll(String regex, String replacement)
- regex :正则表达式
- replacement :用于替换的字符串
replaceAll() 方法用于将目标字符串中匹配某正则表达式的所有子字符串替换成新的字符串
字符串比较
equals() 方法
语法格式:str1.equals(str2)
str1 和 str2 可以是字符串变量, 也可以是字符串字面量。 例如:
1 | "Hello".equals(greeting) |
使用案例:
1 | String str1 = "abc"; |
equalsIgnoreCase() 方法
语法格式:str1.equalsIgnoreCase(str2)
equalsIgnoreCase() 方法的作用和语法与 equals() 方法完全相同,唯一不同的是 equalsIgnoreCase() 比较时不区分大小写。
案例:
1 | String str1 = "abc"; |
equals()与==的比较
equals() 方法比较字符串对象中的字符。
==运算符比较两个对象引用看它们是否引用相同的实例。
compareTo() 方法
语法格式:str.compareTo(String otherstr);
compareTo() 方法用于按字典顺序比较两个字符串的大小,该比较是基于字符串各个字符的 Unicode 值。
如果按字典顺序 str 位于 otherster 参数之前,比较结果为一个负整数;如果 str 位于 otherstr 之后,比较结果为一个正整数;如果两个字符串相等,则结果为 0。
案例:
1 | public static void main(String[] args) { |
输出:
1 | str = A |
字符串查找
根据字符查找
indexOf() 方法
语法格式:
1 | str.indexOf(value) |
- str :指定字符串
- value :待查找的字符(串)
- fromIndex :查找时的起始索引, fromIndex 默认为 0。
indexOf() 方法用于返回字符(串)在指定字符串中首次出现的索引位置,如果能找到,则返回索引值,否则返回 -1。
案例:
1 | String s = "Hello Java"; |
lastlndexOf() 方法
语法格式:
1 | str.lastIndexOf(value) |
lastIndexOf() 方法用于返回字符(串)在指定字符串中最后一次出现的索引位置,如果能找到则返回索引值,否则返回 -1。
注意:lastIndexOf() 方法的查找策略是从右往左查找,如果不指定起始索引,则默认从字符串的末尾开始查找。
案例:
1 | public static void main(String[] args) { |
输出:
1 | public static void main(String[] args) { |
根据索引查找
语法格式:字符串名.charAt(索引值)
案例:
1 | String words = "today,monday,sunday"; |
Java中容易混淆的空格串和null
“”是一个长度为 0 且占内存的空字符串,在内存中分配一个空间,可以使用 Object 对象中的方法。例如:“”.toString() 等。
null 是空引用,表示一个对象的值,没有分配内存,调用 null 的字符串的方法会抛出空指针异常。例如如下代码:
1 | String str = null; |
new String() 创建一个字符串对象的默认值为 “”,String 类型成员变量的初始值为 null。
空字符串 “” 是长度为 0 的字符串。可以调用以下代码检查一个字符串是否为空:
if (str.length() == 0)
或
if (str.equals(""))
空字符串是一个 Java 对象,有自己的串长度(0)和内容(空)。不过,String 变量还可以存放一个特殊的值,名为 null,这表示目前没有任何对象与该变量关联。要检查一个字符串是否为 null,要使用以下条件:
if (str == null)
有时要检查一个字符串既不是 null 也不为空串,这种情况下就需要使用以下条件:
if (str != null && str.length() != 0)
注意:首先要检查 str 不为 null。如果在一个 null 值上调用方法,会出现错误。
示例如下:
1 | public static void main(String[] args) { |
Java字符串的简单加密解密
这里就介绍异或加解密
1)创建一个静态的 encryptAndDencrypt() 方法,在该方法中传入两个参数。代码如下:
1 | public static String encryptAndDencrypt(String value, char secret) { |
上述代码首先将需要加密的内容转换为字节数组,接着遍历字节数组中的内容,在 for 语句中通过异或运算进行加密,然后将加密后的字符串保存到 newresult 变量中。最后返回 newresult 变量的值。
2)在 main() 方法中添加代码,接收用户在控制台输入的内容并输出,然后调用 encryptAndUncrypt() 方法对字符串分别进行加密和解密,并将加密和解密后的内容输出。代码如下:
1 | public static void main(String[] args) { |
3)执行上述代码进行测试,如下所示。
1 | 请输入您想加密的内容: |
Java StringBuffer类
StringBuffer 类是可变字符串类,创建 StringBuffer 类的对象后可以随意修改字符串的内容。每个 StringBuffer 类的对象都能够存储指定容量的字符串,如果字符串的长度超过了 StringBuffer 类对象的容量,则该对象的容量会自动扩大。
StringBuffer()构造一个空的字符串缓冲区,并且初始化为 16 个字符的容量。StringBuffer(int length)创建一个空的字符串缓冲区,并且初始化为指定长度 length 的容量。StringBuffer(String str)创建一个字符串缓冲区,并将其内容初始化为指定的字符串内容 str,字符串缓冲区的初始容量为 16 加上字符串 str 的长度。
案例:
1 | // 定义一个空的字符串缓冲区,含有16个字符的容量 |
追加字符串
StringBuffer 类的 append() 方法用于向原有 StringBuffer 对象中追加字符串。
语法格式:StringBuffer 对象.append(String str)
替换字符
StringBuffer 类的 setCharAt() 方法用于在字符串的指定索引位置替换一个字符。
语法格式:StringBuffer 对象.setCharAt(int index, char ch)
案例:
1 | StringBuffer sb = new StringBuffer("hello"); |
反转字符串
StringBuffer 类中的 reverse() 方法用于将字符串序列用其反转的形式取代。
语法格式:StringBuffer 对象.reverse();
案例:
1 | StringBuffer sb = new StringBuffer("java"); |
删除字符串
StringBuffer 类提供了 deleteCharAt() 和 delete() 两个删除字符串的方法,如下。
1. deleteCharAt() 方法
语法格式:StringBuffer 对象.deleteCharAt(int index)
deleteCharAt() 方法用于移除序列中指定位置的字符,然后将剩余的内容形成一个新的字符串。
案例:
1 | StringBuffer sb = new StringBuffer("She"); |
2. delete() 方法
语法格式:StringBuffer 对象.delete(int start,int end)
- start :要删除字符的起始索引值(包括索引值所对应的字符)
- end :要删除字符串的结束索引值(不包括索引值所对应的字符)。
delete() 方法用于移除序列中子字符串的字符
案例:
1 | StringBuffer sb = new StringBuffer("hello jack"); |
String、StringBuffer和StringBuilder的区别
在 Java 中字符串属于对象,Java 提供了 String 类来创建和操作字符串,而且String 类是不可变类。
Java 提供了两个可变字符串类 StringBuffer 和 StringBuilder,中文翻译为“字符串缓冲区”。
StringBuffer、StringBuilder、String 中都实现了 CharSequence 接口。CharSequence 是一个定义字符串操作的接口,它只包括 length()、charAt(int index)、subSequence(int start, int end) 这几个 API。
StringBuffer、StringBuilder、String 对 CharSequence 接口的实现过程不一样,如下图4-1所示:
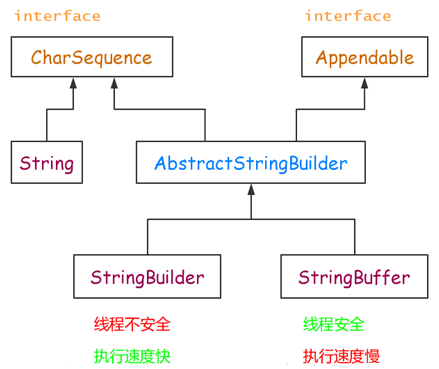
图4-1 对CharSequence接口的实现
String 是 Java 中基础且重要的类,String 是 Java 中基础且重要的类,拼接字符串时候会产生很多无用的中间对象。
StringBuffer 提供了 append 和 add 方法,它的本质是一个线程安全的可修改的字符序列。
很多情况下我们的字符串拼接操作不需要线程安全,所以 StringBuilder 登场,它去掉了保证线程安全的那部分,减少了开销。
线程安全:
StringBuffer:线程安全
StringBuilder:线程不安全
速度:
一般情况下,速度从快到慢为 StringBuilder > StringBuffer > String,当然这是相对的,不是绝对的。
使用环境:
操作少量的数据使用 String。
单线程操作大量数据使用 StringBuilder。
多线程操作大量数据使用 StringBuffer。
Java正则表达式
String 类里提供了如下几个特殊的方法。
- boolean matches(String regex):判断该字符串是否匹配指定的正则表达式。
- String replaceAll(String regex, String replacement):将该字符串中所有匹配 regex 的子串替换成 replacement。
- String replaceFirst(String regex, String replacement):将该字符串中第一个匹配 regex 的子串替换成 replacement。
- String[] split(String regex):以 regex 作为分隔符,把该字符串分割成多个子串。
正则表达式支持字符
| 字符 | 解释 |
|---|---|
| X | 字符x(x 可代表任何合法的字符) |
| \0mnn | 八进制数 0mnn 所表示的字符 |
| \xhh | 十六进制值 0xhh 所表示的字符 |
| \uhhhh | 十六进制值 0xhhhh 所表示的 Unicode 字符 |
| \t | 制表符(“\u0009”) |
| \n | 新行(换行)符(‘\u000A’) |
| \r | 回车符(‘\u000D’) |
| \f | 换页符(‘\u000C’) |
| \a | 报警(bell)符(‘\u0007’) |
| \e | Escape 符(‘\u001B’) |
| \cx | x 对应的的控制符。例如,\cM匹配 Ctrl-M。x 值必须为 A |
表4-0 正则表达式所支持的合法字符
除此之外,正则表达式中有一些特殊字符,这些特殊字符在正则表达式中有其特殊的用途,比如前面介绍的反斜线\。
如果需要匹配这些特殊字符,就必须首先将这些字符转义,也就是在前面添加一个反斜线\。正则表达式中的特殊字符如表 4-1 所示。
| 特殊字符 | 说明 |
|---|---|
| $ | 匹配一行的结尾。要匹配 $ 字符本身,请使用\$ |
| ^ | 匹配一行的开头。要匹配 ^ 字符本身,请使用\^ |
| () | 标记子表达式的开始和结束位置。要匹配这些字符,请使用\(和\) |
| [] | 用于确定中括号表达式的开始和结束位置。要匹配这些字符,请使用\[和\] |
| {} | 用于标记前面子表达式的出现频度。要匹配这些字符,请使用\{和\} |
| * | 指定前面子表达式可以出现零次或多次。要匹配 * 字符本身,请使用\* |
| + | 指定前面子表达式可以出现一次或多次。要匹配 + 字符本身,请使用\+ |
| ? | 指定前面子表达式可以出现零次或一次。要匹配 ?字符本身,请使用\? |
| . | 匹配除换行符\n之外的任何单字符。要匹配.字符本身,请使用\. |
| \ | 用于转义下一个字符,或指定八进制、十六进制字符。如果需匹配\字符,请用\\ |
| | | 指定两项之间任选一项。如果要匹配丨字符本身,请使用| |
表4-1 正则表达式中的特殊字符
将上面多个字符拼起来,就可以创建一个正则表达式。例如:
1 | "\u0041\\\\" // 匹配 A\ |
。正则表达式中的“通配符”远远超出了普通通配符的功能,它被称为预定义字符,正则表达式支持如表 4-2 所示的预定义字符。
| 预定义字符 | 说明 |
|---|---|
| . | 可以匹配任何字符 |
| \d | 匹配 0~9 的所有数字 |
| \D | 匹配非数字 |
| \s | 匹配所有的空白字符,包括空格、制表符、回车符、换页符、换行符等 |
| \S | 匹配所有的非空白字符 |
| \w | 匹配所有的单词字符,包括 0~9 所有数字、26 个英文字母和下画线_ |
| \W | 匹配所有的非单词字符 |
表4-2 预定义字符
助记法:
- d 是 digit 的意思,代表数字。
- s 是 space 的意思,代表空白。
- w 是 word 的意思,代表单词。
- d、s、w 的大写形式恰好匹配与之相反的字符。
有了上面的预定义字符后,接下来就可以创建更强大的正则表达式了。例如:
1 | c\\wt // 可以匹配cat、cbt、cct、cOt、c9t等一批字符串 |
在一些特殊情况下,例如,若只想匹配 a~f 的字母,或者匹配除 ab 之外的所有小写字母,或者匹配中文字符,上面这些预定义字符就无能为力了,此时就需要使用方括号表达式,方括号表达式有如表 4-3 所示的几种形式。
| 方括号表达式 | 说明 |
|---|---|
| 表示枚举 | 例如[abc]表示 a、b、c 其中任意一个字符;[gz]表示 g、z 其中任意一个字符 |
| 表示范围:- | 例如[a-f]表示 a[\\u0041-\\u0056]表示十六进制字符 \u0041 到 \u0056 范围的字符。范围可以和枚举结合使用,如[a-cx-z],表示 a |
| 表示求否:^ | 例如[^abc]表示非 a、b、c 的任意字符;[^a-f]表示不是 a~f 范围内的任意字符 |
| 表示“与”运算:&& | 例如 [a-z&&[def]]是 af[a-z&&^bc]]是 a[ad-z] [a-z&&[m-p]]是 a |
| 表示“并”运算 | 并运算与前面的枚举类似。例如[a-d[m-p]]表示 [a-dm-p] |
表4-3 方括号表达式
方括号表达式比前面的预定义字符灵活多了,几乎可以匹配任何字符。例如,若需要匹配所有的中文字符,就可以利用 [\\u0041-\\u0056] 形式——因为所有中文字符的 Unicode 值是连续的,只要找出所有中文字符中最小、最大的 Unicode 值,就可以利用上面形式来匹配所有的中文字符。
正则表达式还支持圆括号,用于将多个表达式组成一个子表达式,圆括号中可以使用或运算符|。例如,正则表达式“((public)|(protected)|(private))”用于匹配 Java 的三个访问控制符其中之一。
除此之外,Java 正则表达式还支持如表 5 所示的几个边界匹配符。
| 边界匹配符 | 说明 |
|---|---|
| ^ | 行的开头 |
| $ | 行的结尾 |
| \b | 单词的边界 |
| \B | 非单词的边界 |
| \A | 输入的开头 |
| \G | 前一个匹配的结尾 |
| \Z | 输入的结尾,仅用于最后的结束符 |
| \z | 输入的结尾 |
表4-4 边界匹配符
前面例子中需要建立一个匹配 000-000-0000 形式的电话号码时,使用了 \d\d\d-\d\d\d-\d\d\d\d 正则表达式,这看起来比较烦琐。实际上,正则表达式还提供了数量标识符,正则表达式支持的数量标识符有如下几种模式。
- Greedy(贪婪模式):数量表示符默认采用贪婪模式,除非另有表示。贪婪模式的表达式会一直匹配下去,直到无法匹配为止。如果你发现表达式匹配的结果与预期的不符,很有可能是因为你以为表达式只会匹配前面几个字符,而实际上它是贪婪模式,所以会一直匹配下去。
- Reluctant(勉强模式):用问号后缀(?)表示,它只会匹配最少的字符。也称为最小匹配模式。
- Possessive(占有模式):用加号后缀(+)表示,目前只有 Java 支持占有模式,通常比较少用。
三种模式的数量表示符如表 4-5 所示。
| 贪婪模式 | 勉强模式 | 占用模式 | 说明 |
|---|---|---|---|
| X? | X?? | X?+ | X表达式出现零次或一次 |
| X* | X*? | X*+ | X表达式出现零次或多次 |
| X+ | X+? | X++ | X表达式出现一次或多次 |
| X{n} | X{n}? | X{n}+ | X表达式出现 n 次 |
| X{n,} | X{n,}? | X{n,}+ | X表达式最少出现 n 次 |
| X{n,m} | X{n,m}? | X{n,m}+ | X表达式最少出现 n 次,最多出现 m 次 |
表4-5 三种模式的数量表示符
关于贪婪模式和勉强模式的对比,看如下代码:
1 | String str = "hello,java!"; |
当从“hello java!”字符串中查找匹配\\w*子串时,因为\w*使用了贪婪模式,数量表示符*会一直匹配下去,所以该字符串前面的所有单词字符都被它匹配到,直到遇到空格,所以替换后的效果是“■,Java!”;如果使用勉强模式,数量表示符*会尽量匹配最少字符,即匹配 0 个字符,所以替换后的结果是“■hello,java!”。
Pattern和Macher的使用
java.util.regex 是一个用正则表达式所订制的模式来对字符串进行匹配工作的类库包。它包括两个类:Pattern 和 Matcher。
Pattern 对象是正则表达式编译后在内存中的表示形式,因此,正则表达式字符串必须先被编译为 Pattern 对象,然后再利用该 Pattern 对象创建对应的 Matcher 对象。执行匹配所涉及的状态保留在 Matcher 对象中,多个 Matcher 对象可共享同一个 Pattern 对象。
因此,典型的调用顺序如下:
1 | // 将一个字符串编译成 Pattern 对象 |
上面定义的 Pattern 对象可以多次重复使用。如果某个正则表达式仅需一次使用,则可直接使用 Pattern 类的静态 matches() 方法,此方法自动把指定字符串编译成匿名的 Pattern 对象,并执行匹配,如下所示。
1 | boolean b = Pattern.matches ("a*b","aaaaab"); // 返回 true |
上面语句等效于前面的三条语句。但采用这种语句每次都需要重新编译新的 Pattern 对象,不能重复利用已编译的 Pattern 对象,所以效率不高。Pattern 是不可变类,可供多个并发线程安全使用。
Matcher 类提供了几个常用方法,如表 4-6 所示。
| 名称 | 说明 |
|---|---|
| find() | 返回目标字符串中是否包含与 Pattern 匹配的子串 |
| group() | 返回上一次与 Pattern 匹配的子串 |
| start() | 返回上一次与 Pattern 匹配的子串在目标字符串中的开始位置 |
| end() | 返回上一次与 Pattern 匹配的子串在目标字符串中的结束位置加 1 |
| lookingAt() | 返回目标字符串前面部分与 Pattern 是否匹配 |
| matches() | 返回整个目标字符串与 Pattern 是否匹配 |
| reset() | 将现有的 Matcher 对象应用于一个新的字符序列。 |
表4-6
在 Pattern、Matcher 类的介绍中经常会看到一个 CharSequence 接口,该接口代表一个字符序列,其中 CharBuffer、String、StringBuffer、StringBuilder 都是它的实现类。简单地说,CharSequence 代表一个各种表示形式的字符串。
通过 Matcher 类的 find() 和 group() 方法可以从目标字符串中依次取出特定子串(匹配正则表达式的子串),例如互联网的网络爬虫,它们可以自动从网页中识别出所有的电话号码。下面程序示范了如何从大段的字符串中找出电话号码。
1 | public class FindGroup { |
运行上面程序,看到如下运行结果:
1 | 13500006666 |
从上面运行结果可以看出,find() 方法依次查找字符串中与 Pattern 匹配的子串,一旦找到对应的子串,下次调用 find() 方法时将接着向下查找。
提示:通过程序运行结果可以看出,使用正则表达式可以提取网页上的电话号码,也可以提取邮件地址等信息。如果程序再进一步,可以从网页上提取超链接信息,再根据超链接打开其他网页,然后在其他网页上重复这个过程就可以实现简单的网络爬虫了。
find() 方法还可以传入一个 int 类型的参数,带 int 参数的 find() 方法将从该 int 索引处向下搜索。start() 和 end() 方法主要用于确定子串在目标字符串中的位置,如下程序所示。
1 | public class StartEnd { |
上面程序使用 find()、group() 方法逐项取出目标字符串中与指定正则表达式匹配的子串,并使用 start()、end() 方法返回子串在目标字符串中的位置。运行上面程序,看到如下运行结果:
1 | 目标字符串是:Java is very easy! |
matches() 和 lookingAt() 方法有点相似,只是 matches() 方法要求整个字符串和 Pattern 完全匹配时才返回 true,而 lookingAt() 只要字符串以 Pattern 开头就会返回 true。reset() 方法可将现有的 Matcher 对象应用于新的字符序列。看如下例子程序。
1 | public class MatchesTest { |
上面程序创建了一个邮件地址的 Pattern,接着用这个 Pattern 与多个邮件地址进行匹配。当程序中的 Matcher 为 null 时,程序调用 matcher() 方法来创建一个 Matcher 对象,一旦 Matcher 对象被创建,程序就调用 Matcher 的 reset() 方法将该 Matcher 应用于新的字符序列。
从某个角度来看,Matcher 的 matches()、lookingAt() 和 String 类的 equals() 有点相似。区别是 String 类的 equals() 都是与字符串进行比较,而 Matcher 的 matches() 和 lookingAt() 则是与正则表达式进行匹配。
事实上,String 类里也提供了 matches() 方法,该方法返回该字符串是否匹配指定的正则表达式。例如:
1 | "kongyeeku@163.com".matches("\\w{3,20}@\\w+\\.(com|org|cn|net|gov)"); // 返回 true |
除此之外,还可以利用正则表达式对目标字符串进行分割、查找、替换等操作,看如下例子程序。
1 | public class ReplaceTest { |
上面程序使用了 Matcher 类提供的 replaceAll() 把字符串中所有与正则表达式匹配的子串替换成“哈哈:)”,实际上,Matcher 类还提供了一个 replaceFirst(),该方法只替换第一个匹配的子串。运行上面程序,会看到字符串中所有以“re”开头的单词都会被替换成“哈哈:)”。
实际上,String 类中也提供了 replaceAll()、replaceFirst()、split() 等方法。下面的例子程序直接使用 String 类提供的正则表达式功能来进行替换和分割。
1 | public class StringReg { |
上面程序只使用 String 类的 replaceFirst() 和 split() 方法对目标字符串进行了一次替换和分割。运行上面程序,会看到如下所示的输出结果。
1 | Java has 哈哈:) expressions in 1.4 |
正则表达式是一个功能非常灵活的文本处理工具,增加了正则表达式支持后的 Java,可以不再使用 StringTokenizer 类(也是一个处理字符串的工具,但功能远不如正则表达式强大)即可进行复杂的字符串处理。