

学习率对损失值甚至深度网络的影响?
学习率如果过大,可能会使损失函数直接越过全局最优点,此时表现为loss过大或者为nan
学习率如果过小,损失函数的变化速度很慢,会大大增加网络的收敛复杂度,并且很容易被困在局部最小值或者鞍点
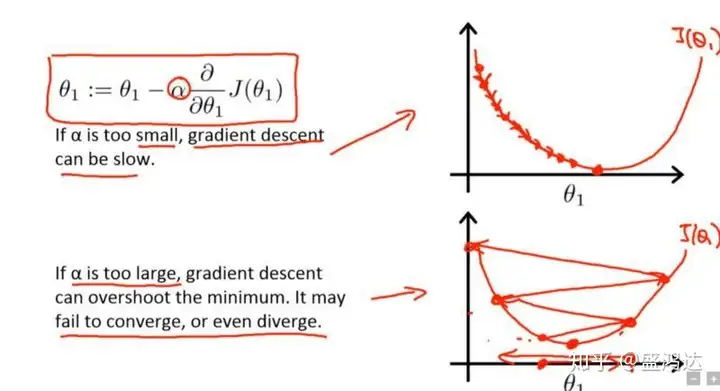
图片来自吴恩达的机器学习课
以上只是从理论上来说明,学习速率对loss值的影响。实际表现中,不同的初始化学习率导致的不同的loss结果如下图。
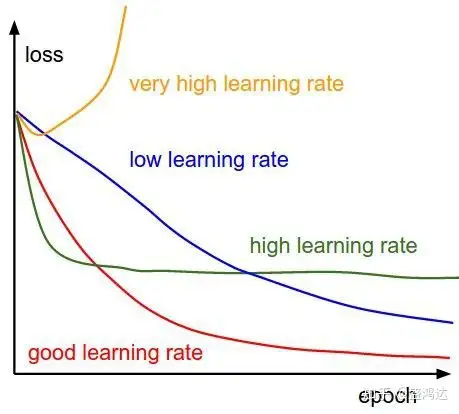
学习率的作用
由以上可以看出,为深度网络选择一个良好的学习率更新策略,可以抽象为以下两点好处:
- 更快地达到loss的最小值
- 保证收敛的loss值是神经网络的全局最优解
如何选择学习率?
现阶段研究中,共同认同的学习率设置标准为:首先设置一个较大的学习率,使网络的损失值快速下降,然后随着迭代次数的增加一点点减少学习率,防止越过全局最优解。
那么我们现在面临两个两个问题:
- 如何选取初始的学习率
- 如何根据迭代次数更新学习率(即衰减学习率策略)
对于问题2有两类解决方法:
- 从初始学习率不停地向下衰减,策略一般有如下三种方式:轮数衰减、指数衰减、分数衰减
轮数减缓,如五轮训练后学习率减半,下一个五轮后再次减半;
指数减缓,即学习率按训练轮数增长指数插值递减等;
分数减缓,若原始学习率为
- 设置学习率更新范围(最大值与最小值),使学习率在区间内按照一定的更新策略运行,常用的策略如下图:
“三角方法”
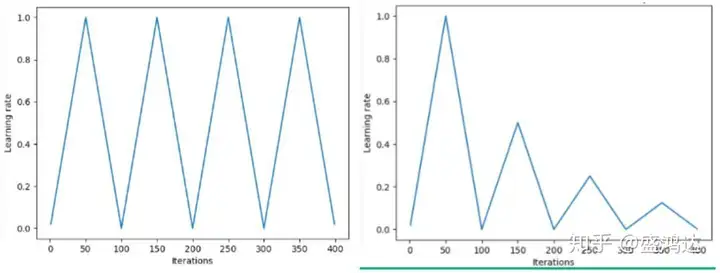
“余弦方法”
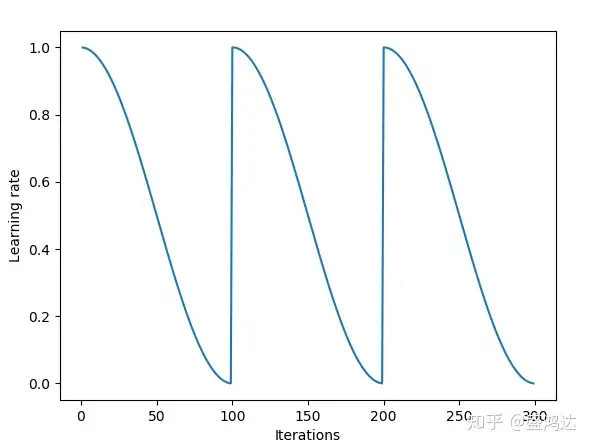
对于问题1,也可以归结为有两类解决方法:
- 大多数的网络的学习率的初始值设置为0.01和0.001为宜
- 在Leslie N. Smith 在2015年的一篇论文中寻找初始学习率的方法
https://arxiv.org/abs/1506.01186arxiv.org/abs/1506.01186
这个方法在论文中是用来估计网络允许的最小学习率和最大学习率,我们也可以用来找我们的最优初始学习率。
首先我们设置一个非常小的初始学习率,比如le-5,然后在每个batch之后都更新网络,同时增加学习率,统计每个batch计算出的loss。
最后我们可以描绘出学习率的变化曲线和loss的变化曲线,从中就能够发现最好的学习率。
下面就是随着迭代次数的增加,学习率不断增加的曲线,以及不同的学习率对应的loss的曲线。
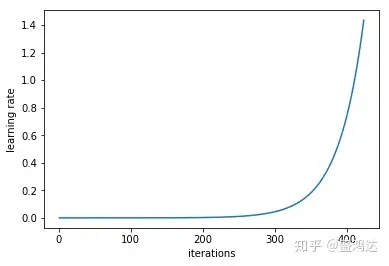
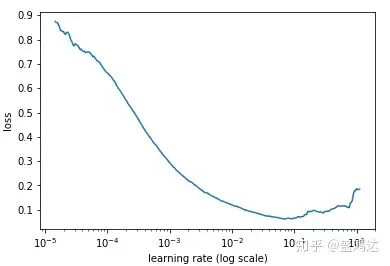
在本例中,最优的学习率变化范围是从 0.001 到 0.01,初始学习率值可以设置为0.01
本文引用自:学习率 - 知乎 (zhihu.com)