根据下面的链接博文,完成程序复现(有github源码):https://www.cnblogs.com/xiaohuiduan/p/16023895.html
相关程序做如下修改和补充:https://blog.csdn.net/baoli8425/article/details/119740795)
增加训练期间的数据可视化 首先得了解 train loss、train acc 以及 test acc 分别是什么
Train Loss: 训练损失是模型在训练集上的表现的一个度量。它反映了模型在预测训练数据时产生的误差的程度。损失函数(例如交叉熵损失,均方误差损失等)是用来计算预测值和真实值之间的差距的。损失越小,说明模型在训练集上的表现越好。
Train Accuracy: 训练准确率是模型在训练集上正确预测的样本数与总样本数的比值。这个比例越高,说明模型在训练集上的表现越好。但是过高的训练准确率可能也会导致过拟合,即模型过度地学习了训练数据,可能在测试集或者新的数据上表现得并不好。
Test Accuracy: 测试准确率是模型在测试集上正确预测的样本数与总样本数的比值。测试集是模型在训练过程中没有见过的数据,所以测试准确率能更好地反映模型的泛化能力,即模型对新数据的处理能力。如果一个模型的测试准确率很高,那么我们可以认为这个模型的性能很好。
这三个指标是深度学习中最常见的评估模型性能的指标,但并不是唯一的。还有其他的一些指标,比如精度、召回率、F1得分等,可以用来更全面地评估模型的性能。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 import torch.optim as optimfrom torch.utils.tensorboard import SummaryWriterimport timelog_writer = SummaryWriter() criterion = nn.CrossEntropyLoss() optimizer = optim.SGD(myNet.parameters(), lr=0.001 , momentum=0.9 ) start_time = time.time() for epoch in range (100 ): myNet.train() loss, acc = train_loss_acc() log_writer.add_scalar("Loss/train" , float (loss), epoch) log_writer.add_scalar("Acc/train" , float (acc), epoch) if epoch % 10 == 0 : print (f"Epoch {epoch + 1 } - Training Loss: {loss} , Training Accuracy: {acc} " ) myNet.eval () acc = test_acc() log_writer.add_scalar("Acc/valid" , float (acc), epoch) if epoch % 10 == 0 : print (f"Epoch {epoch + 1 } - Test Accuracy: {acc} " ) end_time = time.time() total_time = end_time - start_time print (f"Total training time: {total_time} seconds" )
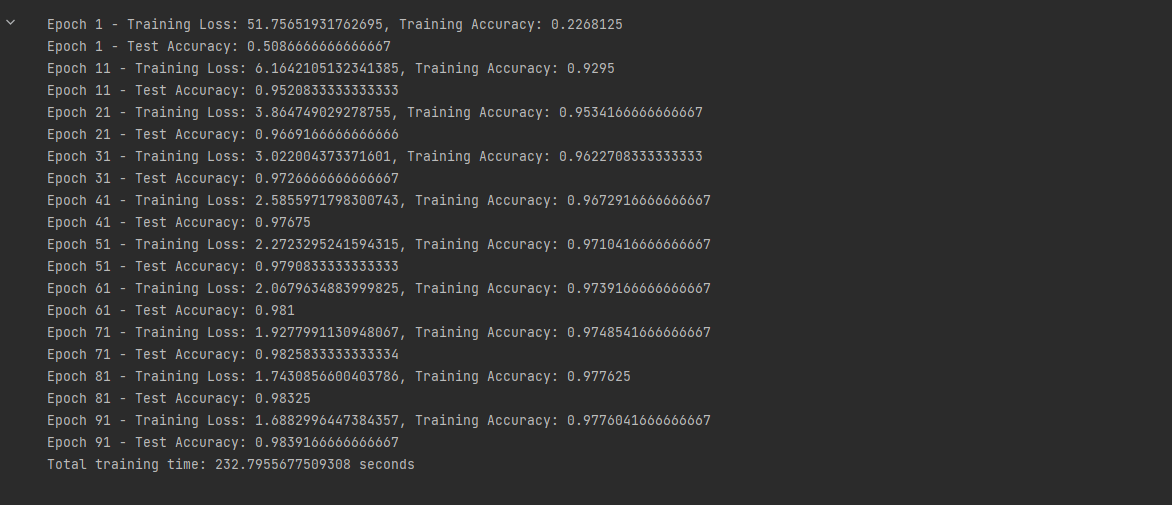
训练期间的输出如下
1 2 from sklearn.model_selection import train_test_splittrain_img,valid_img,train_label,valid_label = train_test_split(train_img,train_label,test_size=0.2 ,shuffle=True )
代码中将train_img,train_label进行划分,划分为训练集 和验证集 。这里使用sklearn中的train_test_split 进行划分,训练集和测试集的比例为 8:2 。
根据训练期间的输出可以看到 train acc 和 test acc 的数值都在不断升高,而 train loss 在不断减小,这说明我们的模型准确率伴随着 epoch 的轮数不断上升随之提升。
用tensorboard显示保存的训练结果 MNIST训练.ipynb训练后就会生成一个logs文件夹
然后在命令行下输入(不需要进入到该目录执行下面指令)
1 tensorboard --logdir "日志所在的目录"
想换端口的话
1 tensorboard --logdir "日志所在的目录" --port=6007
这种写法更好
或者
1 tensorboard --logdir=<directory_name>
注意:日志所在的目录是指日志的目录文件夹,不是日志本身路径。
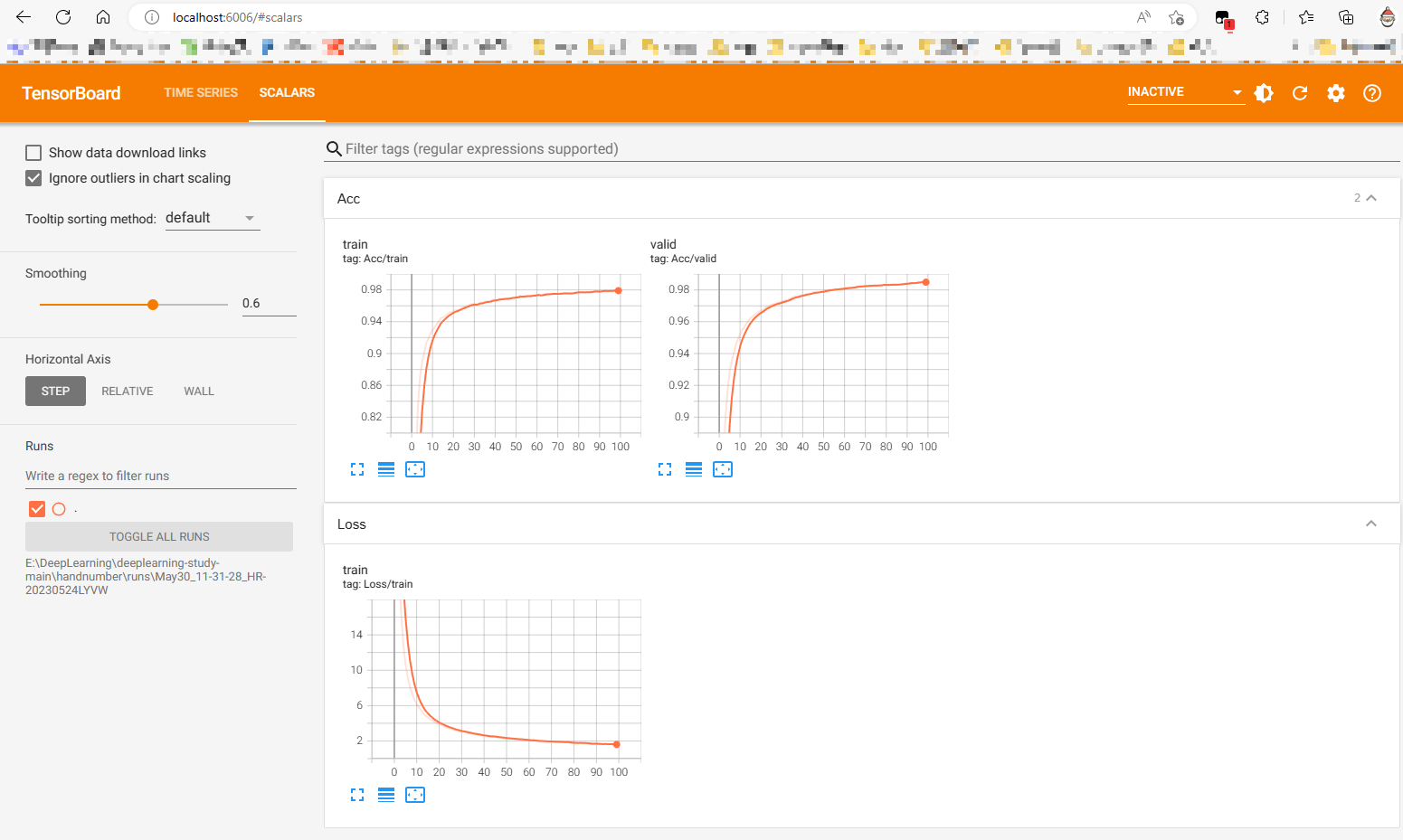
这是最后tensorboard可视化的结果
MNIST验证.ipynb分析 第一部分:读取数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 import numpy as npdef read_image (file_path ): with open (file_path,'rb' ) as f: file = f.read() img_num = int .from_bytes(file[4 :8 ],byteorder='big' ) img_h = int .from_bytes(file[8 :12 ],byteorder='big' ) img_w = int .from_bytes(file[12 :16 ],byteorder='big' ) img_data = [] file = file[16 :] data_len = img_h*img_w for i in range (img_num): data = [item/255 for item in file[i*data_len:(i+1 )*data_len]] img_data.append(np.array(data).reshape(img_h,img_w)) return img_data def read_label (file_path ): with open (file_path,'rb' ) as f: file = f.read() label_num = int .from_bytes(file[4 :8 ],byteorder='big' ) file = file[8 :] label_data = [] for i in range (label_num): label_data.append(file[i]) return label_data test_img = read_image("mnist_data/test/t10k-images.idx3-ubyte" ) test_label = read_label("mnist_data/test/t10k-labels.idx1-ubyte" )
这部分的代码定义了两个函数read_image和read_label,这两个函数被用来从MNIST数据集中读取图像数据和标签数据。MNIST数据集中的数据以特殊的格式存储,这些函数能够读取这些格式,并将数据转换为NumPy数组。
read_image函数打开指定的图像文件,读取图像的数量、高度、宽度,并根据这些信息把图像数据读取为NumPy数组。图像数据首先被归一化到0-1的范围(通过除以255),然后被重塑为图片的高度和宽度。read_label函数打开指定的标签文件,读取标签的数量,然后将标签数据读取为一个NumPy数组。
最后,test_img和test_label是从相应的测试集文件中读取的图像和标签数据。
第二部分:预处理和数据加载
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 import torchfrom torch.utils.data import Dataset,DataLoaderimport torchvisionfrom torchvision import datasets,transformsmy_transforms = transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.1307 ,), (0.3081 ,)) ]) class MnistDataset (Dataset ): def __init__ (self,image,label,my_transforms ): self.len = len (label) self.image = image self.label = label self.my_transforms = my_transforms def __getitem__ (self,index ): return my_transforms(self.image[index]),self.label[index] def __len__ (self ): return self.len
这部分代码首先定义了一些预处理转换,然后定义了一个用于加载MNIST数据的Dataset子类。
my_transforms定义了一个预处理转换的序列,包括将NumPy数组转换为PyTorch张量以及对图像进行归一化。这个归一化是根据MNIST数据集的全局平均值和标准差进行的。MnistDataset类是PyTorch的Dataset类的一个子类,用于加载MNIST数据。它的构造函数接受图像和标签数据以及预处理转换,并将它们保存为实例变量。__getitem__方法返回给定索引处的图像和标签,图像数据首先通过预处理转换。__len__方法返回数据集中的图像数量。
第三部分:设备选择和模型定义
1 2 3 4 import torch.nn as nnimport torch.nn.functional as Fdevice = torch.device("cuda:0" if torch.cuda.is_available() else "cpu" ) print (device)
这部分的代码首先定义了一个用于设备选择的变量,然后定义了一个神经网络模型。
device变量用于设定模型和数据应该在哪个设备(CPU或GPU)上运行。如果有可用的GPU,那么会选择第一个可用的GPU(”cuda:0”);否则,会选择CPU(”cpu”)。这个变量可以在将模型和数据移动到正确设备时使用。
这三个部分的代码都是模型训练和测试过程的重要组成部分,它们分别处理数据读取、预处理和模型定义,是任何深度学习模型都需要的基础步骤。
第四部分:网络模型定义
使用LeNet网络结构
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 class MyNet (nn.Module): def __init__ (self ): super (MyNet,self).__init__() self.conv_1 = nn.Sequential( nn.Conv2d(1 ,32 ,kernel_size=3 ,padding=1 ), nn.ReLU(), nn.BatchNorm2d(32 ), nn.MaxPool2d(2 ,2 ), nn.Dropout(0.25 ) ) self.conv_2 = nn.Sequential( nn.Conv2d(32 ,64 ,kernel_size=3 ,padding=1 ), nn.ReLU(), nn.BatchNorm2d(64 ), nn.MaxPool2d(2 ,2 ), nn.Dropout(0.25 ), ) self.conv_3 = nn.Sequential( nn.Conv2d(64 ,128 ,kernel_size=3 ), nn.ReLU(), nn.BatchNorm2d(128 ), nn.MaxPool2d(2 ,2 ), nn.Dropout(0.25 ), ) self.fc = nn.Sequential( nn.Linear(512 ,128 ), nn.Linear(128 ,10 ) ) def forward (self,x ): x = self.conv_1(x) x = self.conv_2(x) x = self.conv_3(x) x = x.view(x.size(0 ),-1 ) x = self.fc(x) return F.log_softmax(x,dim=1 ) myNet = torch.load("mnist.h5" ).to(device)
这部分的代码定义了一个名为MyNet的神经网络模型。这个模型是torch.nn.Module的子类,它包含三个卷积层序列和一个全连接层序列。每个卷积层序列包含一个卷积层、ReLU激活函数、批量归一化、最大池化以及Dropout。全连接层序列包含两个线性层。
forward方法定义了输入数据通过网络的方式。首先,数据通过三个卷积层序列,然后被展平(x.view(x.size(0),-1)),最后通过全连接层序列。输出使用了log softmax作为激活函数,这在多分类问题中非常常见。
最后,网络模型被从"mnist.h5"文件中加载,然后被移动到先前定义的设备(CPU或GPU)上。
第五部分:测试数据加载和模型评估
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 testDataset = MnistDataset(test_img,test_label,my_transforms) test_loader = DataLoader(testDataset,256 ) def test_loss_acc (): correct = 0 total = 0 for data in test_loader: test_imgs,test_labels = data test_imgs = test_imgs.type (torch.FloatTensor) outputs = myNet(test_imgs.to(device)).to("cpu" ) _,predict_labels = torch.max (outputs,1 ) total += test_labels.size(0 ) mask = predict_labels == test_labels correct += mask.sum ().item() print ("测试集正确率:{}%" .format (100.0 * correct / total)) return total,correct
这部分的代码首先创建一个MnistDataset实例和一个DataLoader实例,用于在测试过程中加载数据。然后定义了一个函数test_loss_acc,用于计算模型在测试集上的正确率。
在test_loss_acc函数中,模型对每批测试数据进行预测,预测的标签与真实标签进行比较,以计算正确预测的数量。最后,函数返回测试集的总数量和正确预测的数量,以及打印出测试集的正确率。
第六部分:模型评估
1 2 3 4 import torch.optim as optimmyNet.eval () test_loss_acc()
这部分的代码首先将模型设置为评估模式,这是因为模型中包含批量归一化和dropout层,这两种层在训练和评估时的行为是不同的。然后调用test_loss_acc函数,对模型进行评估。
手绘数字图片预测 灰度图像处理
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 import cv2import matplotlib.pyplot as pltfrom PIL import Imagepic = 'testx1.png' img = Image.open (pic) ax = plt.subplot(1 , 2 , 1 ) plt.imshow(img) plt.gray() ax.get_xaxis().set_visible(False ) ax.get_yaxis().set_visible(False ) ax = plt.subplot(1 , 2 , 2 ) target_shape = (28 ,28 ) img2 = cv2.imread(pic, cv2.IMREAD_GRAYSCALE) img2 = cv2.resize(img2, target_shape) plt.imshow(img2, cmap='gray' ) ax.get_xaxis().set_visible(False ) ax.get_yaxis().set_visible(False ) plt.show()
运用上面代码我们可以还原手绘图像的灰度图,这就是我们的模型最终接收的图片,经过预测结果和灰度图的对比我们可以发现某些规律。
其中每张图左侧为手写字原始图片,右侧为生成的灰度图
经过下面的预测程序最终的预测结果是 1 和 3 正确,2 预测错误,原因我后面会说明
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 from PIL import Imagedef hand_drawn_test (uri ): image = Image.open (uri).convert('L' ) image = image.resize((28 , 28 )) image = my_transforms(image) image = image.unsqueeze(0 ) image = image.to(device) output = myNet(image).to("cpu" ) _, predicted = torch.max (output, 1 ) print (f'Predicted label for hand-drawn image: {predicted.item()} ' ) hand_drawn_test("test.png" )
为什么当手写数字图片的画布为白底时会一直识别错误
这是因为 MNIST 数据集的图片都是黑底白字的,即背景(非数字部分)是黑色,而数字部分是白色。这是一个重要的特征,因为它决定了网络需要寻找的特征以及数据的表示方式。
当你提供一个白底黑字的图片给模型时,这个模型可能会困惑,因为它没有在训练数据中看到过这样的图像。具体来说,像素值的分布和模型预期的分布是完全相反的,这可能会导致模型做出错误的预测。
因此,如果你想在手写数字识别任务中使用自己的手绘图片,并且你的模型是在MNIST数据集上训练的,那么你应该确保你的图片也是黑底白字的。
增加混淆矩阵可视化 具体代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 import seaborn as snsimport matplotlib.pyplot as pltimport numpy as npfrom sklearn.metrics import confusion_matriximport pandas as pdtestDataset = MnistDataset(test_img,test_label,my_transforms) test_loader = DataLoader(testDataset,256 ) def test_loss_acc (): all_preds = [] all_labels = [] correct = 0 total = 0 for data in test_loader: test_imgs,test_labels = data test_imgs = test_imgs.type (torch.FloatTensor) outputs = myNet(test_imgs.to(device)).to("cpu" ) _,predict_labels = torch.max (outputs,1 ) all_preds.extend(predict_labels.cpu().numpy()) all_labels.extend(test_labels.cpu().numpy()) total += test_labels.size(0 ) mask = predict_labels == test_labels correct += mask.sum ().item() print ("测试集正确率:{}%" .format (100.0 * correct / total)) conf_mat = confusion_matrix(all_labels, all_preds) df_cm = pd.DataFrame(conf_mat, index=[i for i in range (10 )], columns=[i for i in range (10 )]) heatmap = sns.heatmap(df_cm, annot=True , fmt="d" , cmap="YlGnBu" ) heatmap.yaxis.set_ticklabels(heatmap.yaxis.get_ticklabels(), rotation=0 , ha='right' ) heatmap.xaxis.set_ticklabels(heatmap.xaxis.get_ticklabels(), rotation=45 , ha='right' ) plt.ylabel('True label' ) plt.xlabel('Predicted label' ) plt.show() return total,correct myNet.eval () test_loss_acc()
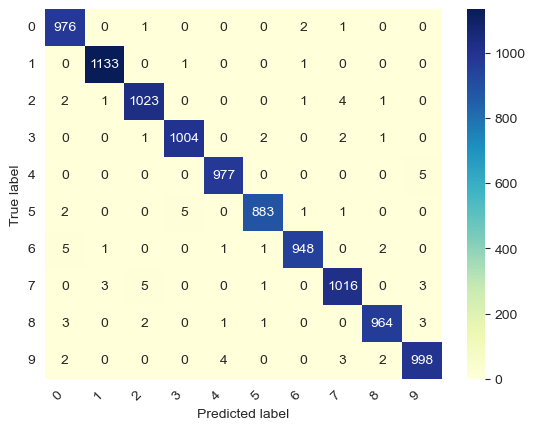
最终混淆矩阵可视化结果如下
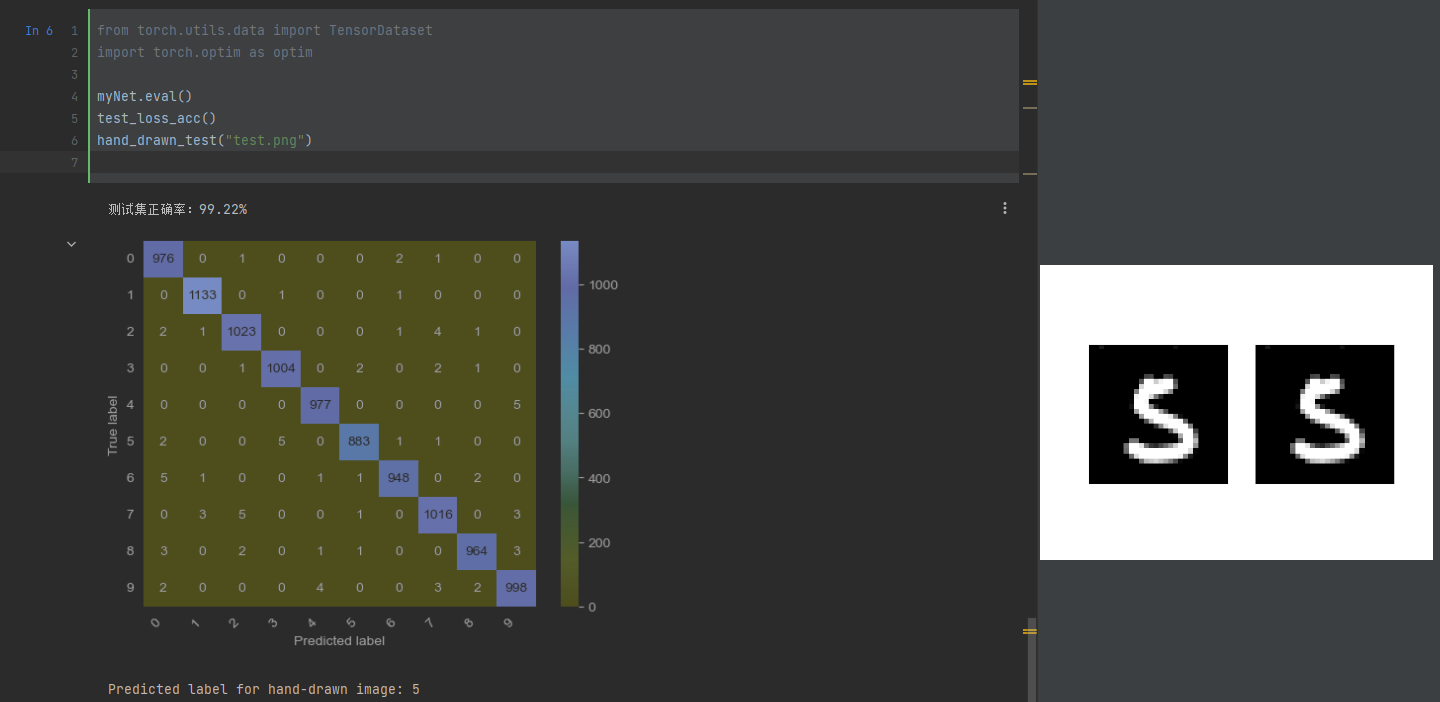
贴一张最终运行结果图
代码地址:GitHub:https://github.com/xiaohuiduan/deeplearning-study/tree/main/手写数字识别
MNIST数字数据集来自:MNIST handwritten digit database, Yann LeCun, Corinna Cortes and Chris Burges